Dieser Artikel gibt Ihnen einen Überblick über Unique-Constraints in SQL und auch den Unique-SQL-Server-Index. Nebenbei werden wir uns die Unterschiede zwischen ihnen ansehen.
Einführung
Einschränkungen in SQL Server ermöglichen es, die Regeln auf Spaltenebene in der SQL-Tabelle zu definieren. Wir können eine Einschränkung mit der Anweisung Tabelle erstellen oder Tabelle ändern hinzufügen. SQL Server erzwingt die ACID-Eigenschaften – Atomicity, Consistency, Isolation und Durability für eine SQL Server-Transaktion.
Wir verwenden Constraints für die Eigenschaft Consistency eines ACID. Das bedeutet, dass nur gültige Daten, die die Bedingung erfüllen, in der Datenbank vorhanden sein sollten.
Sie können diesen Artikel, SQL Server Transaction Overview, durchlesen, um mehr über ACID-Eigenschaften zu erfahren.

In diesem Artikel werden wir uns mit SQL Server Unique Indexes und Unique Constraints beschäftigen. Wir werden auch den Unterschied zwischen ihnen durchgehen.
Überblick über UNIQUE-Beschränkungen in SQL Server
Wir können einen eindeutigen Wert in einer Spalte von SQL Server sicherstellen. Das kann entweder auf einer einzelnen Spalte oder einer Kombination von Spalten sein. Es verhindert, dass Sie doppelte Werte in Spalten haben, die mit der Unique-Beschränkung verbunden sind. Sie kennen vielleicht eine Primärschlüsselspalte, die ebenfalls einen eindeutigen Wert in der Spalte erzwingt. In SQL Server kann es nur einen Primärschlüssel pro Tabelle geben.
Angenommen, Sie haben eine Tabelle „Mitarbeiter“, die, wie der Name schon sagt, alle Informationen über die Mitarbeiter enthält. Wir haben einen Primärschlüssel für die Spalte. Diese Tabelle enthält auch die Sozialversicherungsnummer der Mitarbeiter. Wir möchten keine doppelten Werte in dieser Spalte für die Sozialversicherungsnummer. Wir haben nicht die Möglichkeit, den Primärschlüssel zu definieren, weil unsere Tabelle ihn bereits hat.
Lassen Sie uns eine SQL-Tabelle mit der SSMS-GUI-Methode erstellen. Erweitern Sie die Datenbank und klicken Sie mit der rechten Maustaste auf Tabellen-> Neu->Tabelle.
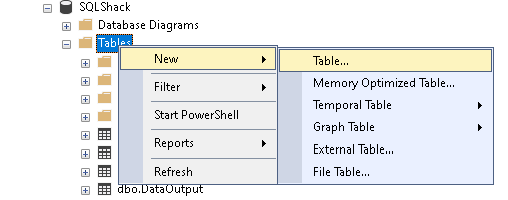
Legen Sie die Spalten und deren Datentyp fest und entfernen Sie das Häkchen bei der Spalte Nullen zulassen.
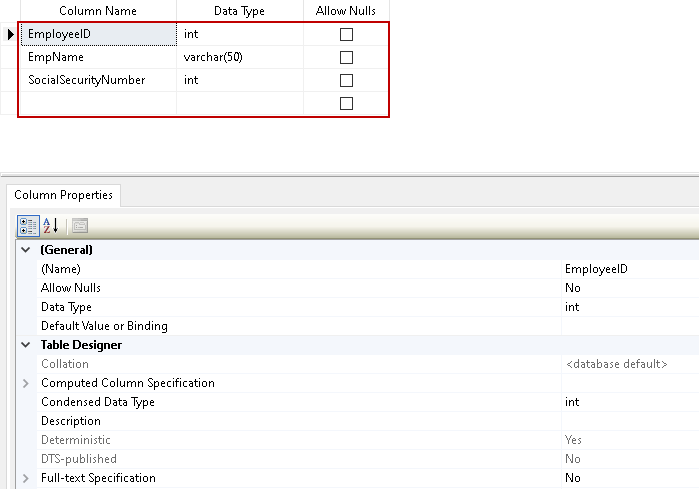
Klicken Sie mit der rechten Maustaste auf die Spalte und aktivieren Sie den Primärschlüssel, indem Sie auf Primärschlüssel setzen klicken.
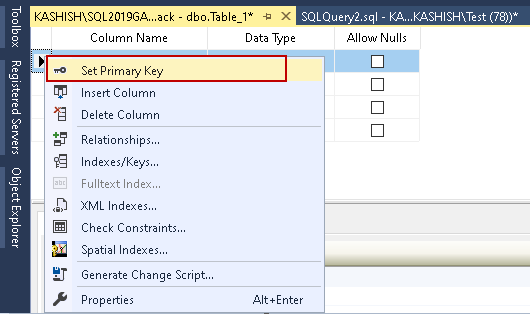
Es wird ein Schlüsselsymbol für die Primärschlüsselspalte gesetzt, wie unten gezeigt.
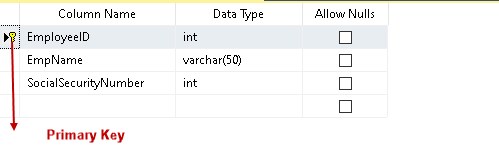
Klicken Sie nun mit der rechten Maustaste auf die Spalte und wählen Sie Indizes/Schlüssel.
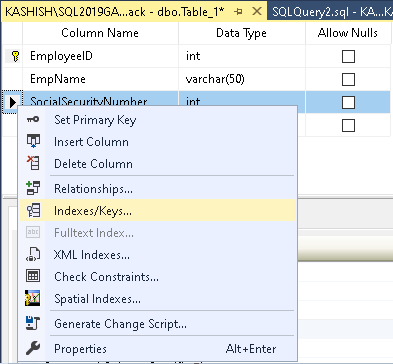
Es öffnet sich der folgende Assistent für Indizes/Schlüssel, der die vorhandenen Indizes anzeigt, da wir bereits einen Primärschlüssel in der Tabelle haben.
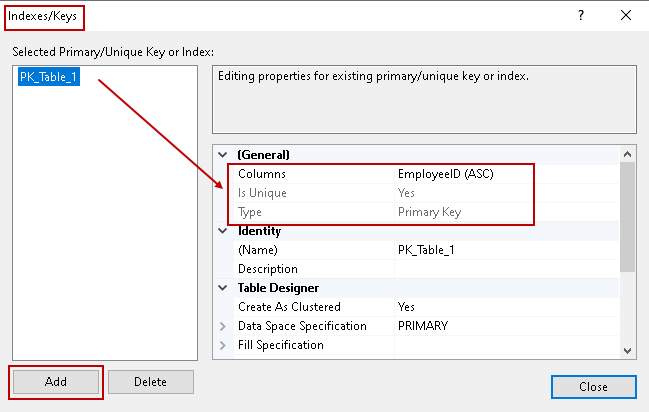
Klicken Sie auf Hinzufügen, und wir können damit weitere Indizes/Einschränkungen definieren.
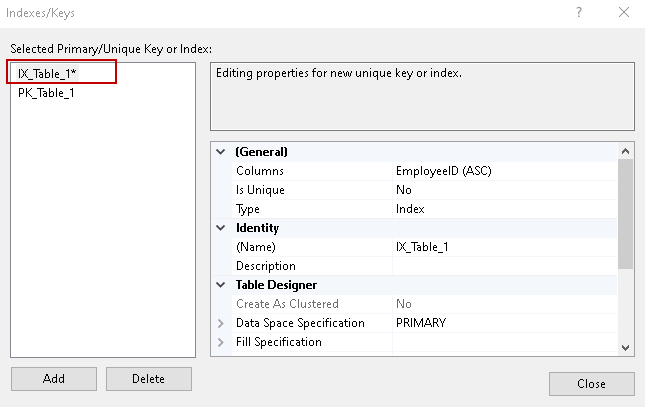
In der Gruppe Allgemein wählen wir die Spalte aus, in der wir einen SQL Server Index definieren wollen. Wir können die Datensortierreihenfolge in aufsteigender (Standard) oder absteigender Reihenfolge auswählen.
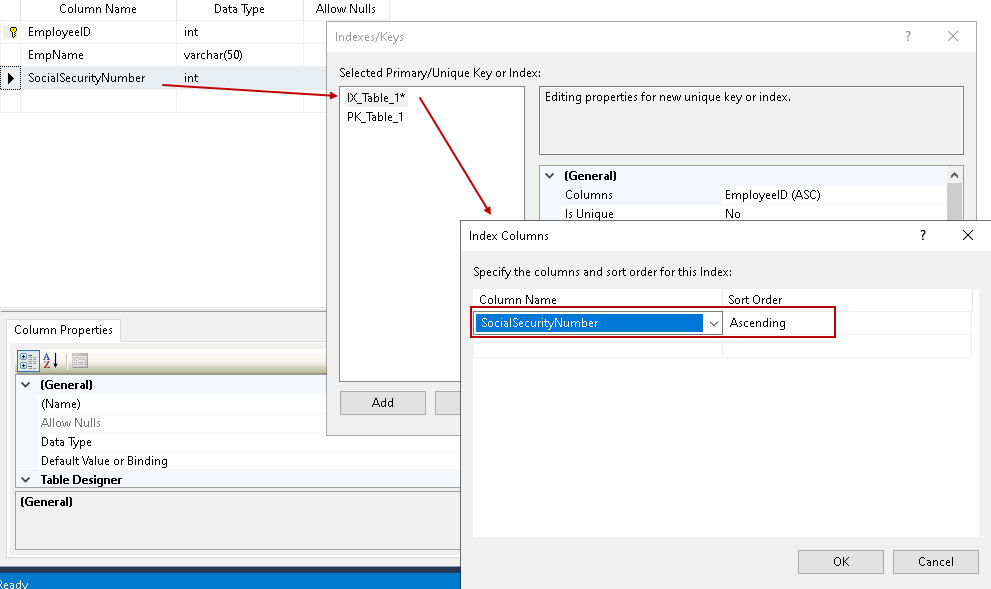
In diesen SQL Server-Indexeigenschaften können wir einen Wert für die Eigenschaft IsUnique auswählen.
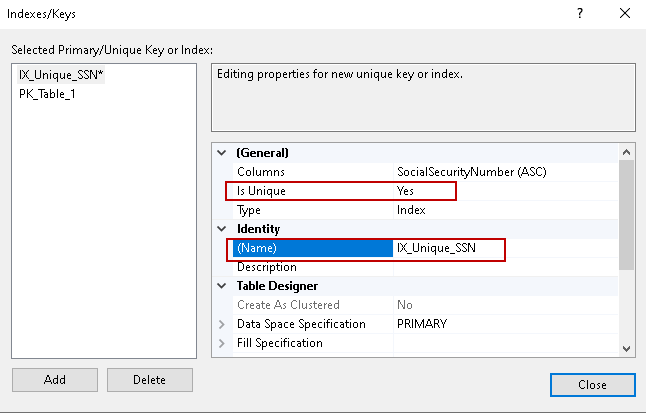
Beim Typ kann man zwischen dem Unique-Schlüssel oder dem Index wählen.
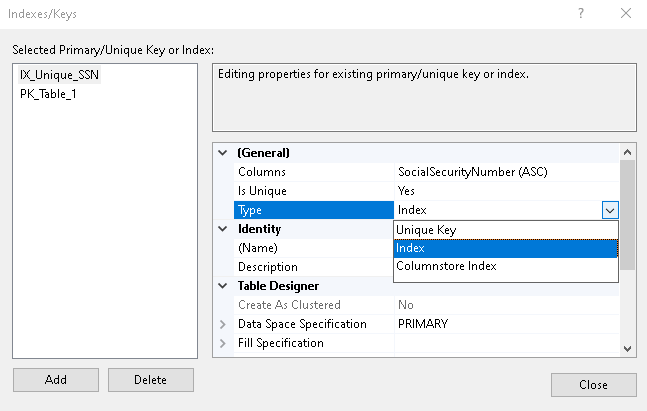
Wählen wir den Unique-Schlüssel aus, so sehen Sie, dass die vorherige Option „Is Unique“ ausgegraut ist. Wir können hier keine Änderung vornehmen, weil der eindeutige Schlüssel für einen eindeutigen Wert in einer Spalte ist.
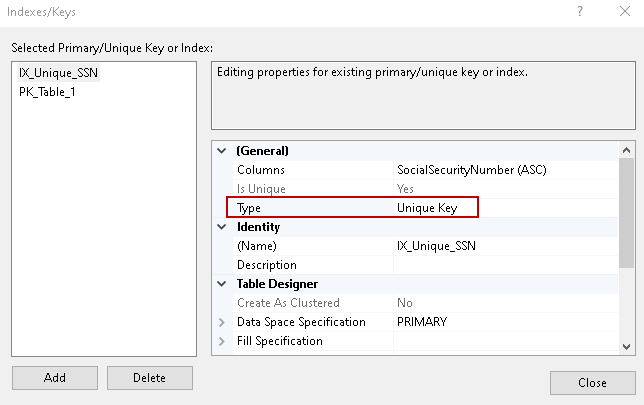
SSSMS gibt Ihnen die Möglichkeit, das Skript für die Arbeit zu generieren, die Sie auf der GUI gemacht haben. Das ist eine gute Sache, besonders für einen Anfänger, der sowohl GUI als auch t-SQL lernt.
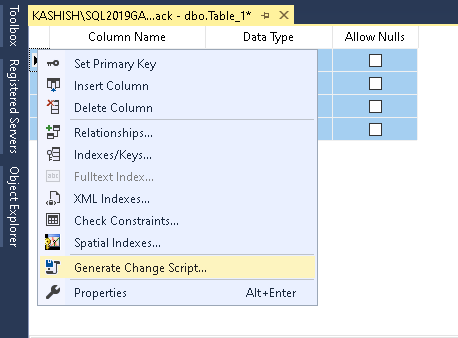
Klicken Sie auf „Änderungsskript generieren…“, und Sie erhalten t-SQL für „Tabelle erstellen“, „Primärschlüssel-Beschränkung hinzufügen“ und „Unique-Beschränkung hinzufügen“ in SQL Server.
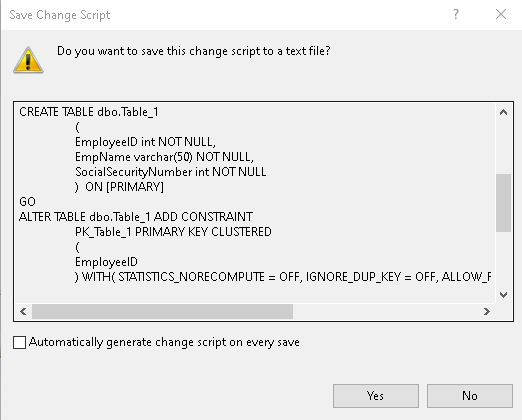
Kopieren Sie dieses Skript und schließen Sie das Fenster des Tabellendesigners, ohne es zu speichern. Wir verwenden das generierte Skript, um die Tabelle und die eindeutige Einschränkung in SQL Server zu erstellen. Den Tabellennamen habe ich so geändert, dass er einen für unsere Demo passenden Namen hat.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
BEGIN TRANSACTION
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
COMMIT
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Employee
(
EmployeeID int NOT NULL,
EmpName varchar(50) NOT NULL,
SocialSecurityNumber int NOT NULL
) ON
GO
ALTER TABLE dbo.Mitarbeiter ADD CONSTRAINT
PK_Tabelle_1 PRIMARY KEY CLUSTERED
(
MitarbeiterID
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
GO
ALTER TABLE dbo.Mitarbeiter ADD CONSTRAINT
IX_Unique_SSN UNIQUE NONCLUSTERED
(
Sozialversicherungsnummer
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
GO
ALTER TABLE dbo.Mitarbeiter SET (LOCK_ESCALATION = TABLE)
GO
COMMIT
|
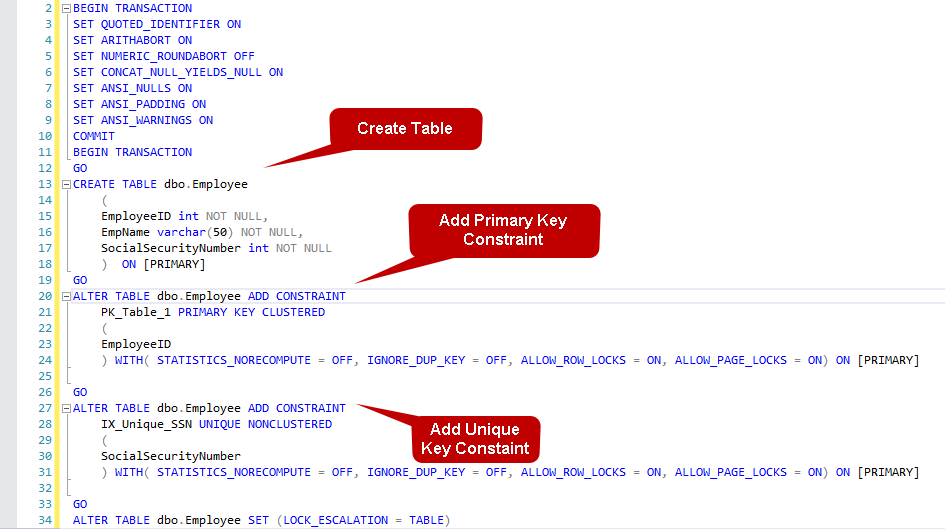
Führen Sie das obige Skript aus, und es erstellt die Tabelle, den Primärschlüssel und die Unique-Key-Beschränkung. Es erstellt den SQL Server-Index für Primärschlüssel- und Unique-Key-Beschränkungen. Vorhandene Indizes für eine Tabelle können wir mit der System Stored Procedure sys.sp_helpindex überprüfen.
|
1
2
|
EXEC sys.sp_helpindex @objname = N’Employee‘
GO
|

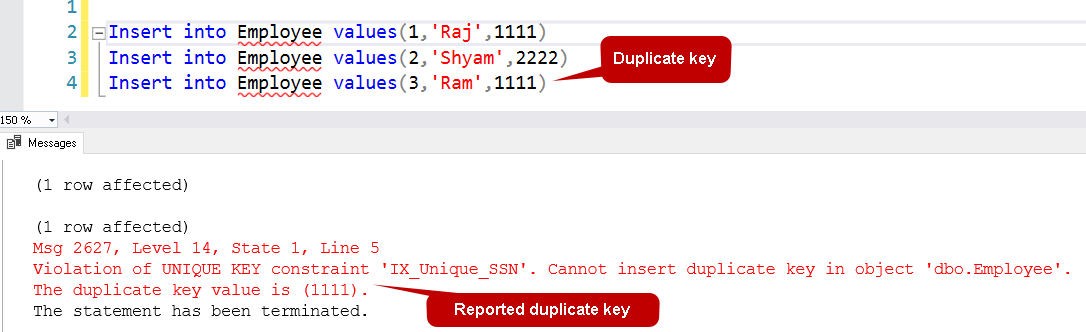
Lassen Sie uns versuchen, einige Werte in diese Tabelle einzufügen und zu sehen, ob wir Duplikate in die Spalte eintragen dürfen.
In der folgenden Abfrage versucht Ram, den Wert in die Spalte einzugeben, der bereits für den Mitarbeiter Raj vorhanden ist.
|
1
2
3
|
Insert into Mitarbeiter Werte(1,’Raj‘,1111)
Insert into Mitarbeiter Werte(2,’Shyam‘,2222)
Insert into Employee values(3,’Ram‘,1111)
|
Die ersten beiden Zeilen werden erfolgreich eingefügt, aber für die dritte Zeile erhalten Sie eine Meldung über eine Verletzung der Unique-Key-Beschränkung. Sie erhalten auch den doppelten Wert in der Ausgabe. Das hilft Ihnen, die problematische Einfügeanweisung, die Probleme verursacht, schnell herauszufinden.
Deaktivieren von Unique Constraints in SQL Server
Wir können eine Unique Constraint mit der folgenden ALTER table-Anweisung deaktivieren.
|
1
2
3
|
ALTER TABLE Employee
NOCHECK CONSTRAINT ALL
GO
|
Dieser Befehl wurde erfolgreich ausgeführt.

Wenn wir versuchen, den doppelten Wert einzugeben, erhalten wir immer noch die gleiche Fehlermeldung.

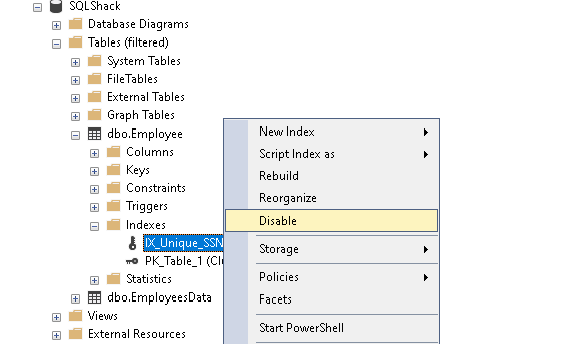
Wir wissen, dass die eindeutige Einschränkung in SQL Server auch einen eindeutigen SQL Server-Index erstellt. In SQL Server können wir einen Index auch deaktivieren, ohne ihn zu löschen.
Klicken Sie mit der rechten Maustaste auf den SQL Server-Index, den wir deaktivieren möchten, und klicken Sie auf Deaktivieren, wie unten gezeigt.
Alternativ können wir den Befehl ALTER INDEX verwenden und den SQL-Server-Index deaktivieren. In dieser Abfrage müssen Sie den Indexnamen und den Tabellennamen angeben.
|
1
2
|
ALTER INDEX IX_Unique_SSN ON Employee
DISABLE
|
Sie können den doppelten Wert in der Spalte eintragen.
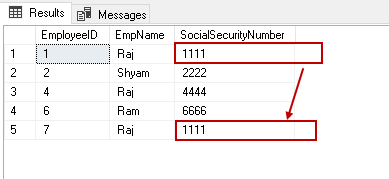
Wir haben einen doppelten Wert in der Tabelle. Lassen Sie uns den eindeutigen, nicht geclusterten Index aktivieren. Um den Index zu aktivieren, müssen wir ihn neu erstellen.
Um einen Index neu zu erstellen, klicken Sie entweder mit der rechten Maustaste auf den Index und klicken Sie in seinen Eigenschaften auf REBUILD.
Wir können den Index auch mit dem folgenden Befehl ALTER INDEX neu aufbauen.
|
1
2
3
|
USE
GO
ALTER INDEX ON . REBUILD
|
Wir können den Index nicht aktivieren, weil ein doppelter Schlüssel existiert und die Einschränkung des eindeutigen Schlüssels keine Duplikate zulässt. Außerdem gibt es doppelte Schlüssel in der Ausgabe.
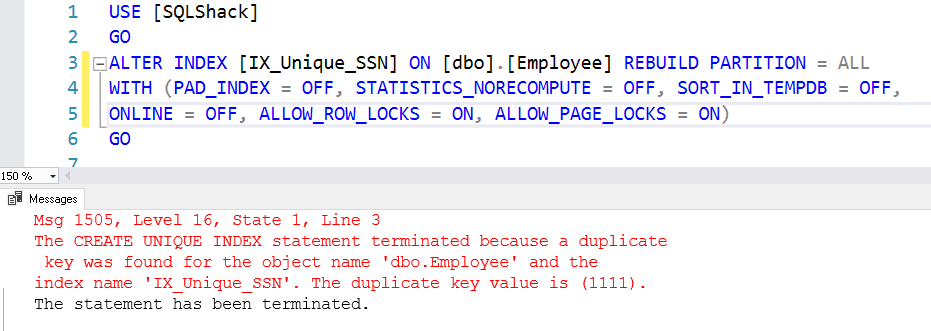
Einschränkungen für eindeutige Schlüssel in SQL Server löschen
Wir können den eindeutigen Index, der durch die eindeutigen Einschränkungen erstellt wurde, nicht löschen. Wenn wir dies versuchen, erhalten wir folgende Fehlermeldung. Es ist nicht möglich, einen Index explizit zu löschen, da die eindeutige Einschränkung den Index verwendet.
|
1
2
|
DROP INDEX Mitarbeiter.
GO
|
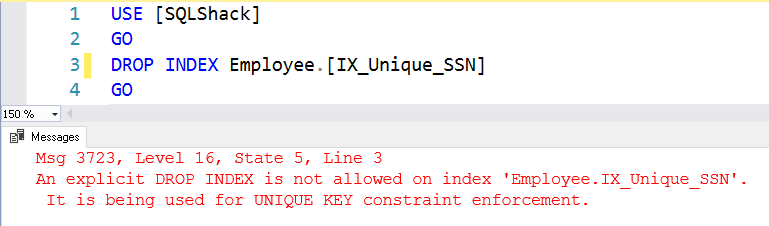
Wir können den Index mithilfe des Befehls „Alter Table Drop Constraint“ löschen. Wie wir wissen, wird in SQL Server ein Index mit einer eindeutigen Einschränkung (Unique Constraint) erstellt. Dieser Befehl löscht den Index zusammen mit der Einschränkung.
|
1
2
|
ALTER TABLE Employee
DROP CONSTRAINT IX_Unique_SSN;
|
Im folgenden Screenshot können wir sehen, dass der Index nicht mehr existiert.
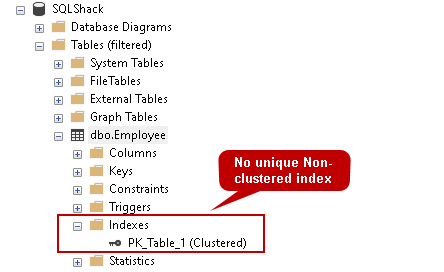
Es hat den zusätzlichen Vorteil, dass niemand versehentlich den durch die eindeutige Einschränkung erstellten Index löschen kann.
Unique Index in SQL Server
Zuvor haben wir Unique Constraints in SQL Server mit der SSMS GUI Methode erstellt. Wir haben keine vorhandenen eindeutigen Beschränkungen für die Tabelle.
Klicken wir mit der rechten Maustaste auf die Tabelle und wählen Design. Es öffnet sich der Tabellendesigner, wie wir ihn bereits gesehen haben.
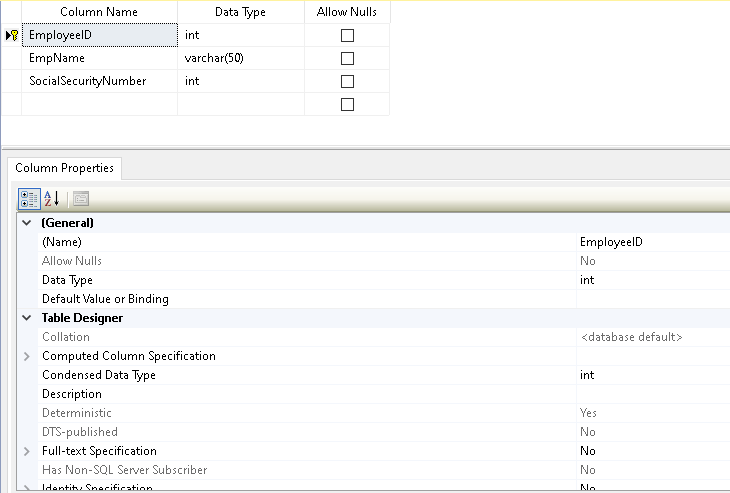
Klicken Sie mit der rechten Maustaste auf , wählen Sie Index/Schlüssel und wählen Sie Index aus der Spalte Typ. Für einen eindeutigen Index wählen Sie für die Spalte den Wert Ja.
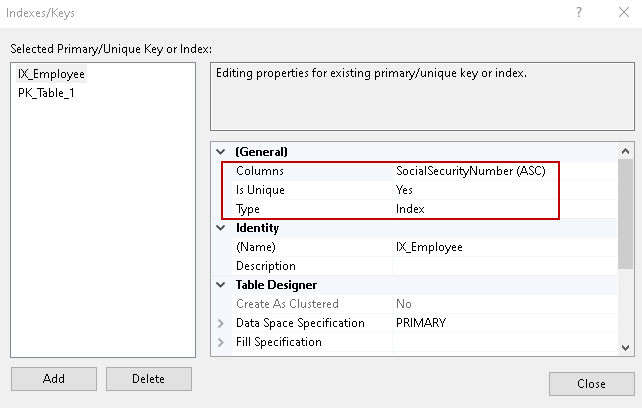
Wir haben auch die wenigen Optionen für eindeutige Indizes aktiviert, wie z. B. doppelte Schlüssel ignorieren und Statistiken neu berechnen.
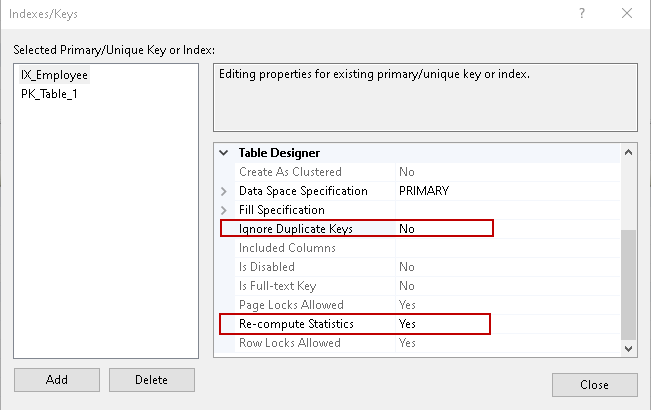
Schließen Sie diese Index/Schlüssel-Seite und erzeugen Sie das Skript. Sie können sehen, dass es einen eindeutigen, nicht geclusterten Index für die Tabelle erstellt.
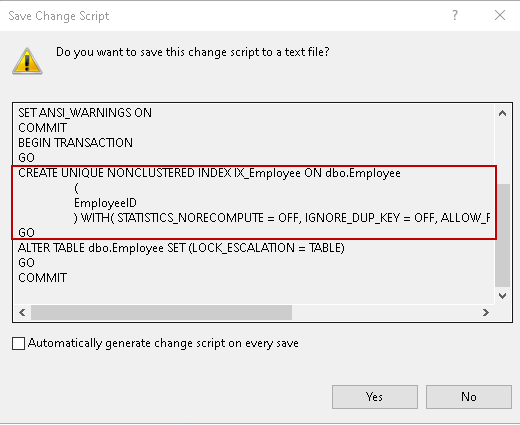
Klicken Sie auf Ok und speichern Sie die vorgenommenen Änderungen. Sie erhalten die Fehlermeldung, weil ein doppelter Schlüssel für die Spalte gefunden wurde.
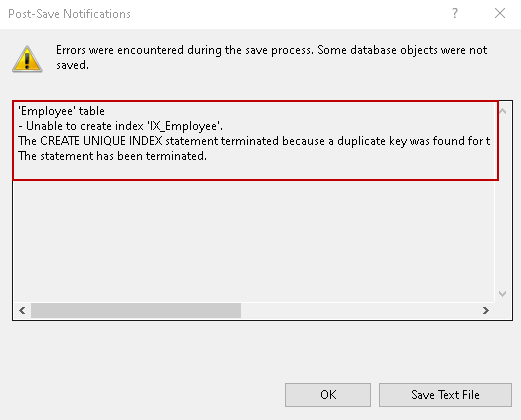
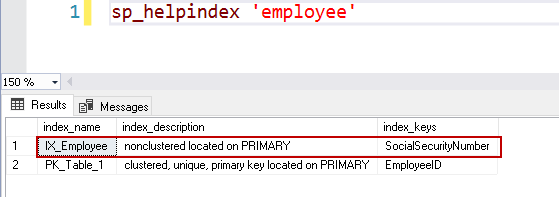
Wir können das Duplikat entfernen, und es wird der Index für Sie erstellt.
Unterschied zwischen Unique-Indizes und Unique-Constraints in SQL Server
Beide, der Unique-Index und der Unique-Constraint, sind ähnlich, und es gibt keinen funktionalen Unterschied zwischen ihnen. Auch der Query Optimizer nutzt den Unique Index, um kostenoptimierte Ausführungspläne zu erstellen. Der einzige Unterschied ist, dass Sie den Unique Index, der durch die Unique Einschränkung in SQL Server erstellt wurde, nicht direkt löschen können. Außerdem erhalten Sie ein paar zusätzliche Indexoptionen, wenn Sie direkt einen Unique Index erstellen.
Wie wir wissen, sind Constraints wie eine Geschäftsregel für Daten, die in SQL Server-Tabellen gespeichert sind. Sie sollten ein Unique Constraint erstellen, wenn Sie nicht direkt mit dem Index arbeiten. Sie sollten jedoch keine eindeutige Einschränkung und keinen Schlüssel für ähnliche Spalten definieren. Es könnte Ihre Abfragen verlangsamen, und außerdem haben Sie doppelte Indizes.

Wir können nicht zwischen einem eindeutigen Schlüssel und einem Index unterscheiden, wenn wir uns die Indizes in der GUI ansehen. Beide existieren im gleichen Index-Ordner in einer Datenbank.
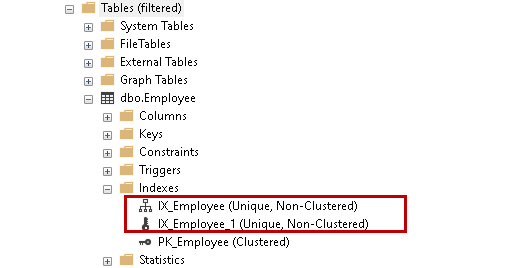
Der SQL Server kennt jedoch den Unterschied. Wenn wir ein Skript für beide Indizes erstellen, sehen Sie unterschiedliche Skripte für beide Indizes. Wie wir unten sehen können, verwendet das erste Skript eine alter table mit Add Constraint Klausel für eine eindeutige Einschränkung in SQL Server, während der spätere Teil die Anweisung Create Non-Clustered Index verwendet.
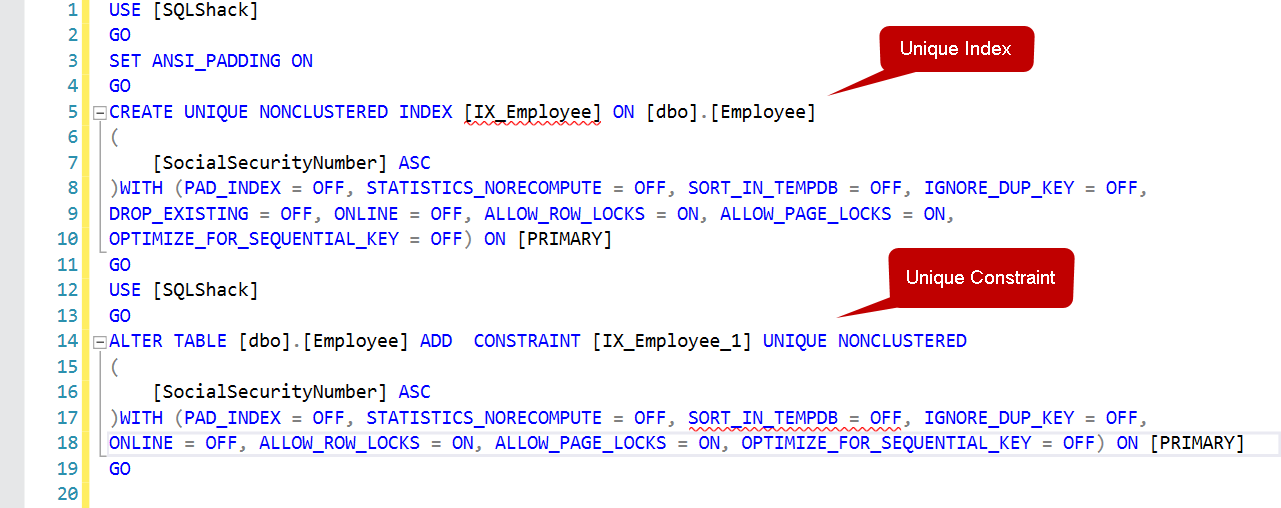
Doch Sie erhalten einige zusätzliche Vorteile mit einem explizit erstellten Unique Index gegenüber Unique Constraints in SQL Server.
- Sie können Spalten in einen Non-Clustered Unique Index aufnehmen, um die Abfrageleistung zu verbessern. SQL Server erzwingt die Eindeutigkeit nur für die Schlüsselspalte eines Unique-Index
- In einem Unique-Index können wir einen Filter hinzufügen. Das kann nützlich sein, wenn Sie einen Unique-Index auf einer Spalte erstellen wollen, die NULL-Werte zulässt. In diesem Fall können wir mehrere NULL-Werte haben, weil ein eindeutiger Index für Nicht-Null-Werte erstellt wird
- Wir können auch einen Fremdschlüssel definieren, der auf einen eindeutigen Schlüsselindex verweist
Abschluss
In diesem Artikel haben wir eindeutige Einschränkungen und eindeutige Indizes in SQL Server untersucht. Einen eindeutigen Index erhalten wir auch, wenn Sie eine eindeutige Einschränkung erstellen. Sie können entscheiden, welche Option für Sie geeignet ist, da es keinen Unterschied in der Abfrageleistung gibt.
- Autor
- Recent Posts

Mit seiner 50-teiligen Serie über SQL Server Always On Availability Groups ist er der Schöpfer einer der größten kostenlosen Online-Sammlungen von Artikeln zu einem einzigen Thema. Aufgrund seines Beitrags zur SQL Server-Community wurde er mit verschiedenen Auszeichnungen geehrt, u.a. wurde er 2020 und 2021 auf der SQLShack kontinuierlich zum „Besten Autor des Jahres“ gekürt.
Raj ist immer an neuen Herausforderungen interessiert, wenn Sie also Beratungshilfe zu einem der in seinen Schriften behandelten Themen benötigen, können Sie ihn unter [email protected] erreichen
Alle Beiträge von Rajendra Gupta anzeigen
- Langfristige Backup-Aufbewahrung für Azure SQL-Datenbank konfigurieren – 25.03, 2021
- Erstellen einer transaktionskonsistenten Kopie der Azure SQL-Datenbank – 22. März 2021
- Ein Überblick über Azure Cloud Shell – 18. März 2021