Este artigo dá-lhe uma comparação de desempenho para NOT IN, SQL Not Exists, SQL LEFT JOIN e SQL EXCEPT.
A biblioteca de comandos T-SQL, disponível no Microsoft SQL Server e actualizada em cada versão com novos comandos e melhorias aos comandos existentes, fornece-nos diferentes formas de executar a mesma acção. Para além de um conjunto de comandos em constante evolução, diferentes programadores aplicarão diferentes técnicas e abordagens aos mesmos conjuntos de problemas e desafios
Por exemplo, três programadores diferentes do SQL Server podem obter os mesmos dados usando três consultas diferentes, tendo cada programador a sua própria abordagem para escrever as consultas do T-SQL para recuperar ou modificar os dados. Mas o administrador da base de dados não ficará necessariamente satisfeito com todas estas abordagens, ele está a olhar para estes métodos a partir de diferentes aspectos nos quais eles podem não se concentrar. Embora todos eles possam obter o mesmo resultado requerido, cada consulta comportar-se-á de forma diferente, consumirá uma quantidade diferente de recursos do SQL Server com tempos de execução diferentes. Todos estes parâmetros que o administrador da base de dados se concentra em moldar o desempenho da consulta. E é regra do administrador da base de dados aqui afinar o desempenho destas consultas e escolher o melhor método com o mínimo efeito possível no desempenho global do SQL Server.
Neste artigo, descreveremos as diferentes formas que podem ser utilizadas para recuperar dados de uma tabela que não existe noutra tabela e comparar o desempenho destas diferentes abordagens. Estes métodos irão utilizar os comandos NOT IN, SQL NOT EXISTS, LEFT JOIN e EXCEPT T-SQL. Antes de iniciar a comparação do desempenho entre os diferentes métodos, forneceremos uma breve descrição de cada um destes comandos T-SQL.
O comando SQL NOT IN permite especificar múltiplos valores na cláusula WHERE. Pode imaginá-lo como uma série de comandos NOT EQUAL TO que estão separados pela condição OR. O comando NO IN compara valores específicos de coluna da primeira tabela com outros valores de coluna da segunda tabela ou de uma subconsulta e devolve todos os valores da primeira tabela que não são encontrados na segunda tabela, sem realizar qualquer filtro para os valores distintos. O NULL é considerado e devolvido pelo comando NOT IN como um valor.
O comando SQL NOT EXISTS é utilizado para verificar a existência de valores específicos na subconsulta fornecida. A subconsulta não retornará quaisquer dados; retorna valores VERDADEIROS ou FALSOS dependendo da verificação da existência de valores da subconsulta.
O comando LEFT JOIN é utilizado para retornar todos os registos da primeira tabela à esquerda, os registos correspondentes da segunda tabela à direita e os valores NULL do lado direito para os registos da tabela à esquerda que não têm correspondência na tabela à direita.
O comando EXCEPTO é utilizado para retornar todos os registos distintos da primeira instrução SELECT que não são retornados da segunda instrução SELECT, com cada instrução SELECT será considerada como um conjunto de dados separado. Por outras palavras, devolve todos os registos distintos do primeiro conjunto de dados e remove desse resultado os registos que são devolvidos do segundo conjunto de dados. Pode imaginá-lo como uma combinação do comando SQL NOT EXISTS e a cláusula DISTINCT. Tenha em consideração que os conjuntos de dados esquerdo e direito do comando EXCEPT devem ter o mesmo número de colunas.
Agora, vejamos, em termos práticos, como poderíamos recuperar dados de um quadro que não existe noutro quadro utilizando métodos diferentes e comparar o desempenho destes métodos para concluir qual o melhor comportamento a adoptar. Vamos começar por criar duas novas tabelas, utilizando o script T-SQL abaixo:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
CREATE TABLE Category_B
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
|
Após a criação das tabelas, preencheremos cada tabela com registos 10K para fins de teste, utilizando o ApexSQL Generate como se mostra abaixo:
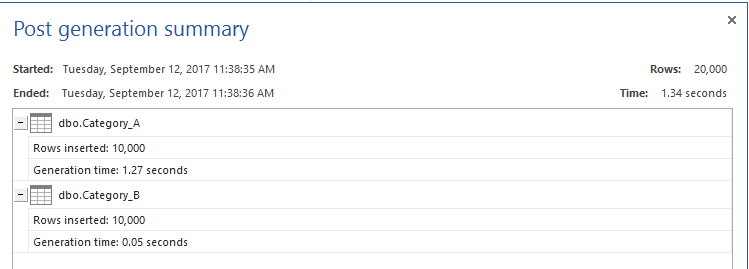
As tabelas de teste estão prontas agora. Vamos permitir que as estatísticas TIME e IO utilizem estas estatísticas para comparar o desempenho dos diferentes métodos. Depois disso, iremos preparar as consultas T-SQL que são utilizadas para puxar os dados que existem na tabela Categoria_A mas não existem na tabela Categoria_B usando quatro métodos; comando NOT IN, comando SQL NOT EXISTS, comando LEFT JOIN e finalmente comando EXCEPT. Isto pode ser conseguido utilizando o script T-SQL abaixo:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
Se executar o script anterior, verá que os quatro métodos retornarão o mesmo resultado, como mostrado no resultado abaixo que contém o número de registos retornados por cada comando:
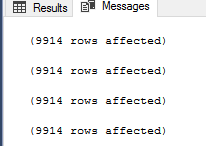
Neste passo, o programador do SQL Server ficará satisfeito, uma vez que qualquer método que venha a utilizar, devolverá o mesmo resultado para ele. Mas e o administrador da base de dados do SQL Server que precisa de verificar o desempenho de cada abordagem? Se analisarmos as estatísticas IO e TIME que são geradas após a execução do script anterior, verá que o script que utiliza o comando NOT IN realiza 10062 leituras lógicas na tabela Category_B, leva 228ms para ser completado com sucesso e 63ms do tempo de CPU, como mostrado abaixo:

Por outro lado, o script que utiliza o comando SQL NOT EXISTS efectua apenas 29 leituras lógicas na tabela Category_B, leva 154ms para ser completado com sucesso e 15ms do tempo da CPU, o que é muito melhor que o método anterior que utiliza NOT IN de todos os aspectos, como se mostra abaixo:

Para o script que usa o comando LEFT JOIN, executa o mesmo número de leituras lógicas que o método anterior SQL NOT EXISTS, que é de 29 leituras lógicas, leva 151ms para ser completado com sucesso e 16ms do tempo da CPU, o que é de alguma forma semelhante às estatísticas derivadas do método anterior SQL NOT EXISTS, como se mostra abaixo:

Finalmente, as estatísticas geradas após a execução do método que utiliza o comando EXCEPT mostram que este executa novamente 29 leituras lógicas, leva 218ms a ser completado com sucesso, e consome 15ms do tempo da CPU, o que é pior que os métodos SQL NOT EXISTS e LEFT JOIN em termos de tempo de execução, como se mostra abaixo:

Até este passo, podemos derivar das estatísticas IO e TIME que os métodos que utilizam os comandos SQL NOT EXISTS e LEFT JOIN actuam da melhor forma, com o melhor desempenho global. Mas será que os planos de execução das consultas nos dirão o mesmo resultado? Vamos verificar os planos de execução que são gerados a partir das consultas anteriores utilizando o ApexSQL Plan, uma ferramenta de análise do plano de consulta do SQL Server.
A janela de resumo de custos dos planos de execução, abaixo, mostra que os métodos que utilizam os comandos SQL NOT EXISTS e LEFT JOIN têm o menor custo de execução, e o método que utiliza o comando NOT IN tem o custo de consulta mais pesado, como se mostra abaixo:

Vamos mergulhar profundamente para compreender como cada método se comporta estudando os planos de execução para estes métodos.
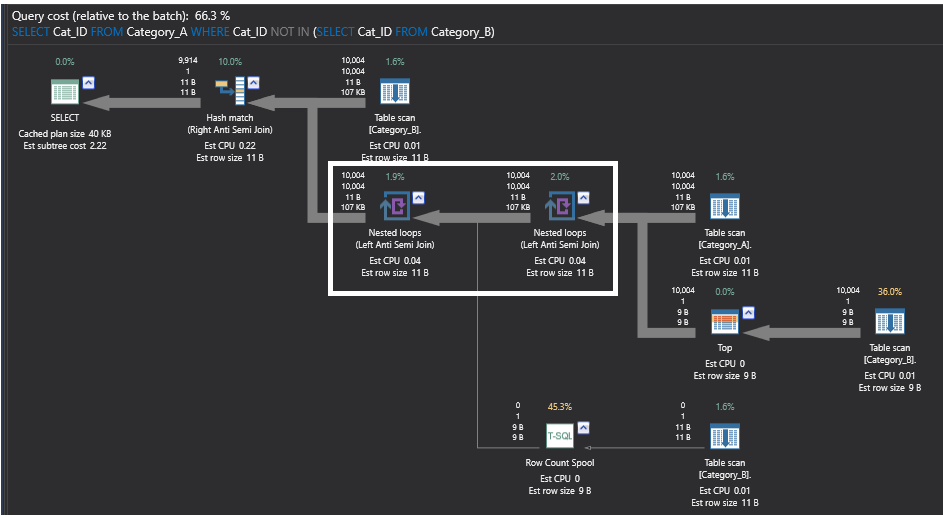
O plano de execução para a consulta que utiliza o comando NOT IN é um plano complexo com número de operadores pesados que realizam operações de looping e contagem. Aquilo em que nos vamos concentrar aqui, para efeitos de comparação de desempenho, são os operadores de looping aninhados. Sob os operadores de Laços Aninhados, pode ver que estes operadores não são verdadeiros operadores de junção, executa algo chamado Left Anti Semi Join. Este operador de junção parcial irá devolver todas as linhas da primeira tabela da esquerda sem linhas correspondentes na segunda tabela da direita, saltando todas as linhas correspondentes entre as duas tabelas. O operador mais pesado no plano de execução abaixo gerado pela consulta usando o comando NOT IN é o operador Row Count Spool, que realiza varreduras na tabela Categoria_B não ordenada, contando quantas linhas são devolvidas, e retorna apenas a contagem das linhas sem quaisquer dados, para fins de verificação da existência de linhas apenas. O plano de execução será o seguinte:
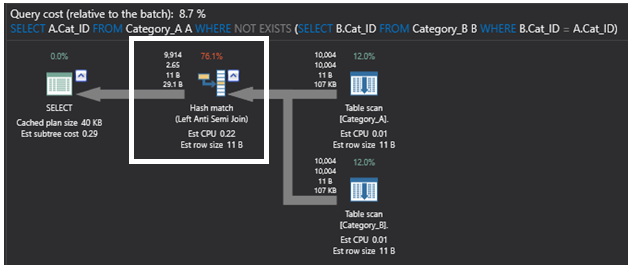
O plano de execução abaixo que é gerado pela consulta usando o comando SQL NOT EXIST é mais simples que o plano anterior, com o operador mais pesado desse plano é o operador Hash Match que executa novamente uma operação de união parcial Left Anti Semi Join que verifica a existência de filas inigualáveis, tal como descrito anteriormente. Este plano será o seguinte:
Comparando o plano de execução anterior gerado pela consulta que usa o comando SQL NOT EXISTS com o plano de execução abaixo que é gerado pela consulta usando o comando LEFT JOIN, o novo plano substitui a união parcial por um operador FILTER que efectua a filtragem IS NULL para os dados devolvidos pelo operador Right OUTER JOIN, que devolve as linhas correspondentes da segunda tabela que podem incluir duplicados. Este plano será o mostrado abaixo:
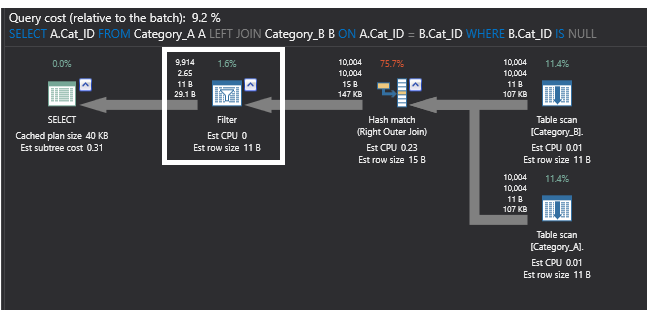
O último plano de execução gerado pela consulta que usa o comando EXCEPT contém também a operação de união parcial Left Anti Semi Join que verifica a existência de filas inigualáveis como mostrado anteriormente. Também realiza uma operação de agregação devido ao grande tamanho da tabela e aos registos não ordenados nela existentes. O processo Hash Aggregate cria uma tabela de hash na memória, o que a torna uma operação pesada, e será calculado um valor de hash para cada linha processada e para cada valor de hash calculado. Depois disso, verifica as filas no balde de hash resultante para as filas de união. O plano será o mostrado abaixo:
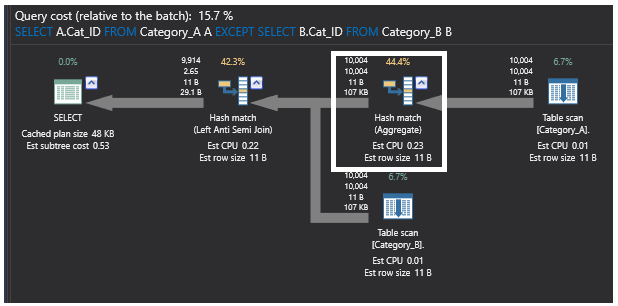
Podemos concluir novamente a partir dos planos de execução anteriores gerados por cada comando utilizado que os dois melhores métodos são os que utilizam os comandos SQL NOT EXISTS e LEFT JOIN. Recordamos que os dados das tabelas anteriores não estão ordenados devido à ausência dos índices. Assim, vamos criar um índice na coluna de junção, o Cat_ID, em ambas as tabelas usando o script T-SQL abaixo:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
UTILIZAÇÃO
GO
CRIAR ÍNDICE NÃO-CLUSTADO EM .
(
ASC
)
GO
CRIAR ÍNDICE NÃO CLUSTERADO LIGADO .
(
ASC
)
GO
|
A janela de resumo de custos dos planos de execução gerada utilizando o Plano ApexSQL depois de executar as declarações SELECT anteriores, mostra que o método que utiliza o comando SQL NOT EXISTS ainda é o melhor e o que utiliza o comando EXCEPT melhorado claramente após a adição dos índices às tabelas, como se mostra abaixo:

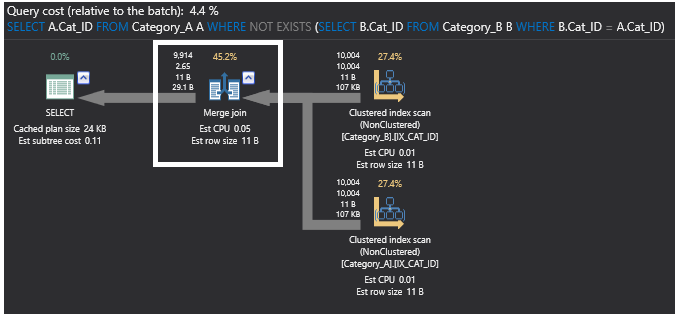
Verificando o plano de execução do comando SQL NOT EXISTS, a anterior operação de união parcial é eliminada agora e substituída pelo operador Merge Join, uma vez que os dados são agora ordenados nas tabelas após a adição dos índices. O novo plano será o mostrado abaixo:
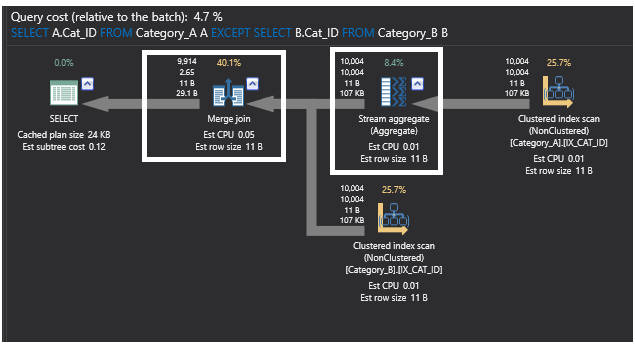
A consulta que usa o comando EXCEPT melhorou claramente depois de adicionar os índices às tabelas e tornar-se um dos melhores métodos para atingir o nosso objectivo aqui. Isto também apareceu no plano de execução da consulta abaixo, no qual a anterior operação de junção parcial é também substituída pelo operador Merge Join, uma vez que os dados são ordenados através da adição dos índices. O operador Hash Aggregate é também substituído agora por um operador Stream Aggregate, uma vez que agrega os dados ordenados após a adição dos índices.
O novo plano será o seguinte:
Conclusion:
SQL Server fornece-nos diferentes formas de recuperar os mesmos dados, deixando ao programador do SQL Server a tarefa de seguir a sua própria abordagem de desenvolvimento para o conseguir. Por exemplo, existem diferentes formas que podem ser utilizadas para recuperar dados de uma tabela que não existem noutra tabela. Neste artigo, descrevemos como obter tais dados usando os comandos NOT IN, SQL NOT EXISTS, LEFT JOIN e EXCEPT T-SQL após fornecer uma breve descrição de cada comando e comparar o desempenho destas consultas. Concluímos, em primeiro lugar, que a utilização dos comandos SQL NOT EXISTS ou LEFT JOIN são a melhor escolha entre todos os aspectos de desempenho. Tentámos também adicionar um índice na coluna de junção em ambas as tabelas, onde a consulta que utiliza o comando EXCEPTO melhorou claramente e mostrou um melhor desempenho, para além do comando SQL NOT EXISTS que continua a ser a melhor escolha em geral.
ligações úteis
- EXISTS (Transact-SQL)
- Subconsultas com EXISTS
- Set Operators – EXCEPT e INTERSECT (Transact-SQL)
- Operador do Showplan Anti-Semi Join esquerdo
- Autor
- Posts recentes

É um Perito em Gestão e Análise de Dados certificado pela Microsoft, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate e Microsoft Certified Trainer.
Também, contribui com as suas dicas SQL em muitos blogs.
Veja todos os posts de Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers – February 11, 2021
- Como monitorizar a Fábrica de Dados Azure – 15 de Janeiro de 2021
- Usando o Controlo da Fonte na Fábrica de Dados Azure – 12 de Janeiro de 2021