W tym artykule przybliżymy temat unikalnych ograniczeń w SQL, a także unikalnego indeksu w SQL Server. Po drodze przyjrzymy się różnicom między nimi.
Wprowadzenie
Constraints w SQL Server pozwala na definiowanie reguł na poziomie kolumny w tabeli SQL. Ograniczenie możemy dodać za pomocą instrukcji Create table lub Alter table. SQL Server wymusza właściwości ACID – Atomicity, Consistency, Isolation i Durability dla transakcji SQL Server.
Wykorzystujemy ograniczenia dla właściwości Consistency w ACID. Oznacza to, że tylko poprawne dane, które spełniają warunek powinny istnieć w bazie danych.
Możesz przejść przez ten artykuł, SQL Server Transaction Overview, aby dowiedzieć się o właściwościach ACID.

W tym artykule poznamy indeksy unikalne i ograniczenia unikalne. Omówimy również różnice pomiędzy nimi.
Przegląd ograniczeń UNIQUE w SQL Server
W SQL Server możemy zapewnić unikalną wartość w kolumnie. Może to być zarówno pojedyncza kolumna jak i kombinacja kolumn. Zapobiega to posiadaniu zduplikowanych wartości w kolumnach powiązanych z ograniczeniem unique. Możesz być zaznajomiony z kolumną klucza podstawowego, która również wymusza unikalną wartość w kolumnie. Możemy mieć tylko jeden klucz główny na tabelę w SQL Server.
Załóżmy, że mamy tabelę Pracownicy i jak sama nazwa wskazuje przechowuje ona wszystkie informacje o pracownikach. Mamy klucz główny dla tej kolumny. Tabela ta przechowuje również numer ubezpieczenia społecznego pracowników. Nie chcemy żadnych zduplikowanych wartości w tej kolumnie numeru ubezpieczenia społecznego. Nie mamy możliwości zdefiniowania klucza głównego, ponieważ nasza tabela już go posiada.
Twórzmy tabelę SQL za pomocą GUI SSMS. Rozwijamy bazę danych i klikamy prawym przyciskiem myszy na Tables-> New->Table.
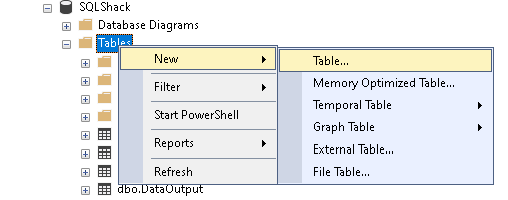
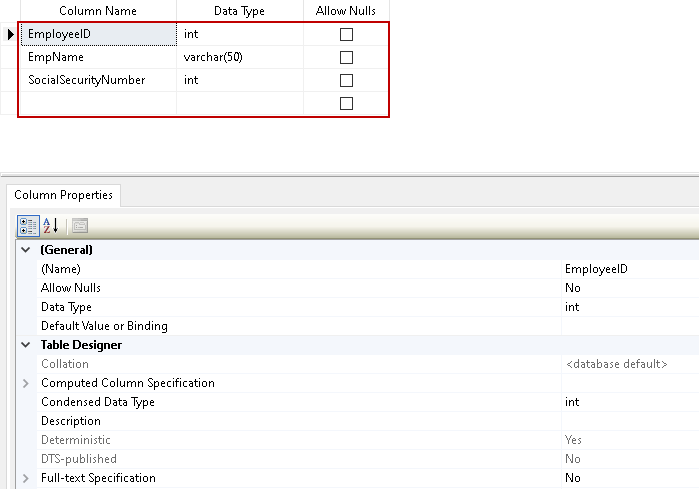
Podaj kolumny, ich typ danych oraz usuń zaznaczenie dla kolumny Allow Nulls.
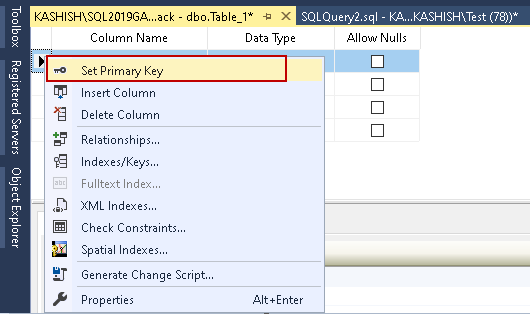
Kliknij prawym przyciskiem myszy na kolumnę i włącz klucz podstawowy klikając na niej przycisk Ustaw klucz podstawowy.
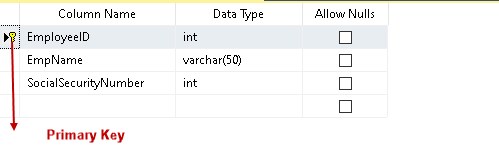
Ustawia symbol klucza dla kolumny z kluczem podstawowym, jak pokazano poniżej.
Teraz klikamy prawym przyciskiem myszy na kolumnie i wybieramy opcję Indeksy/Klucze.
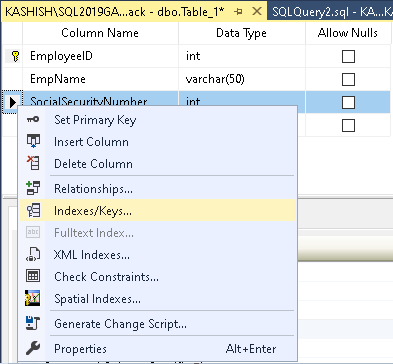
Otwiera to następujący kreator indeksów/kluczy, który pokazuje istniejące indeksy jak mamy już klucz główny na tabeli.
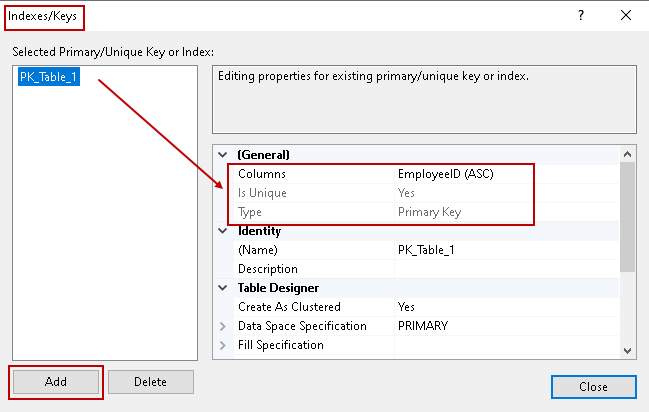
Kliknij na Dodaj i możemy zdefiniować dodatkowe indeksy/ograniczenia za pomocą tego.
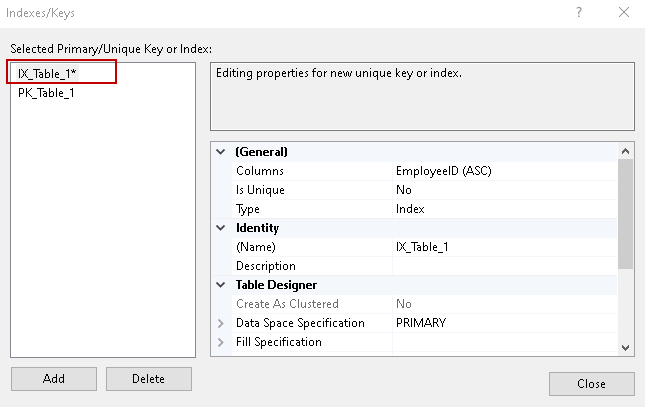
W grupie General wybieramy kolumnę, w której chcemy zdefiniować SQL Server Index. Możemy wybrać kolejność sortowania danych rosnąco (domyślnie) lub malejąco (domyślnie).
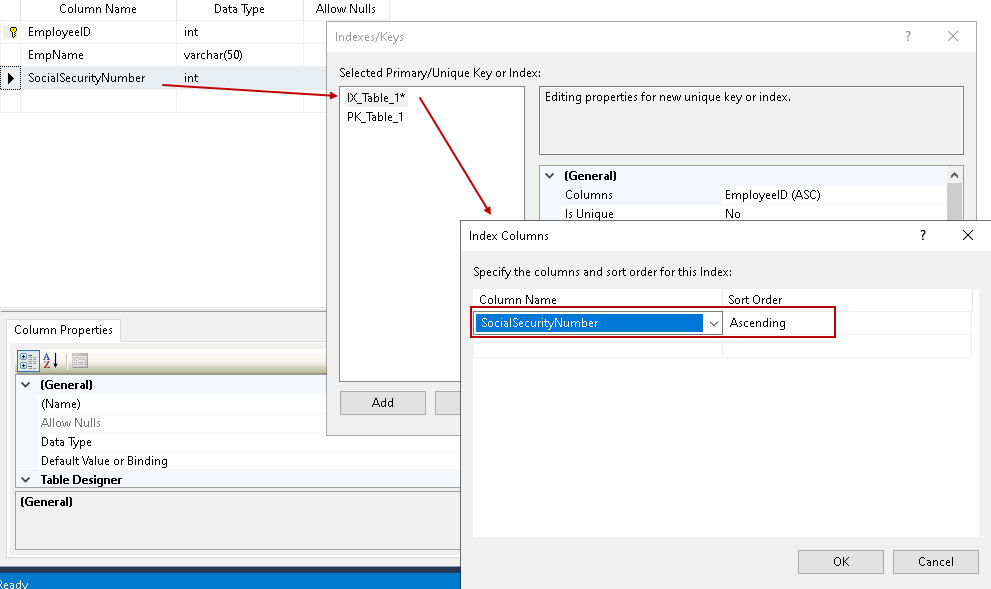
Właściwości indeksu SQL Server możemy wybrać wartość dla właściwości – IsUnique.
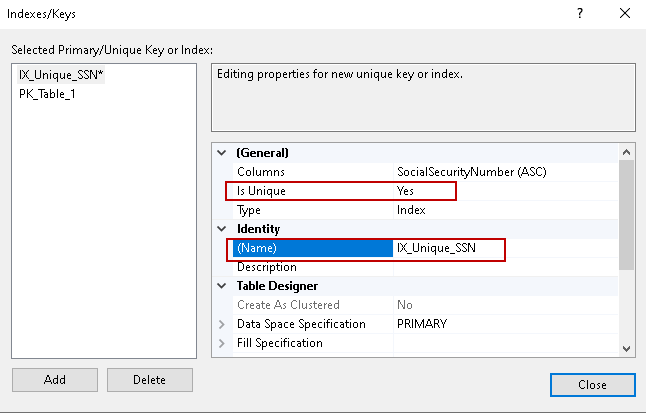
W typie otrzymujemy możliwość wyboru spośród Unikalny klucz lub Indeks.
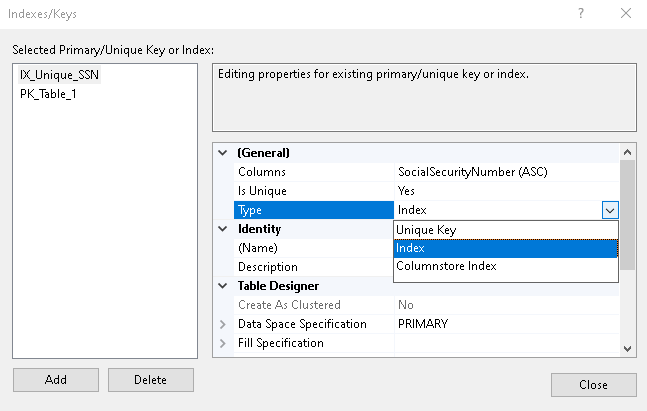
Wybierzmy Klucz unikalny i widzimy, że poprzednia opcja „Is Unique” jest wyszarzona. Nie możemy tutaj nic zmienić, ponieważ klucz unikalny jest dla unikalnej wartości w kolumnie.
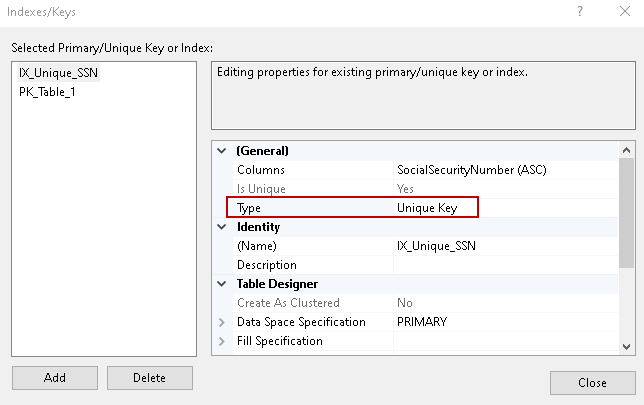
SSMS daje możliwość wygenerowania skryptu do pracy, którą wykonaliśmy na GUI. Jest to dobra rzecz, szczególnie dla początkującego użytkownika, który musi nauczyć się zarówno GUI jak i t-SQL.
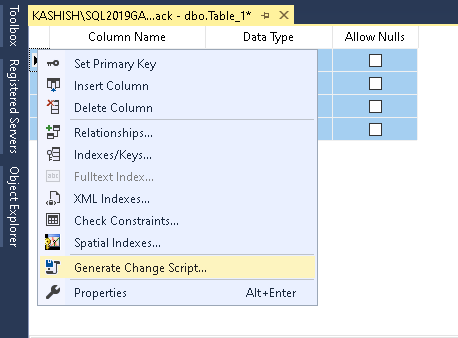
Kliknij na Generate Change Script…, a otrzymasz t-SQL dla Create table, add primary key constraint i add the unique constraint w SQL Server.
Skopiuj ten skrypt i zamknij okno projektanta tabel bez zapisywania go. Wygenerowany skrypt wykorzystujemy do utworzenia tabeli i unikalnego ograniczenia w SQL Server. Zmodyfikowałem nazwę tabeli, aby miała odpowiednią nazwę dla naszego demo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
BEGIN TRANSACTION
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET. NUMERIC_ROUNDABORT OFF
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
COMMIT
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Employee
(
EmployeeID int NOT NULL,
EmpName varchar(50) NOT NULL,
SocialSecurityNumber int NOT NULL
) ON
GO
ALTER TABLE dbo.Employee ADD CONSTRAINT
PK_Table_1 PRIMARY KEY CLUSTERED
(
EmployeeID
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
GO
ALTER TABLE dbo.Employee ADD CONSTRAINT
IX_Unique_SSN UNIQUE NONCLUSTERED
(
SocialSecurityNumber
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
GO
ALTER TABLE dbo.Employee SET (LOCK_ESCALATION = TABLE)
GO
COMMIT
|
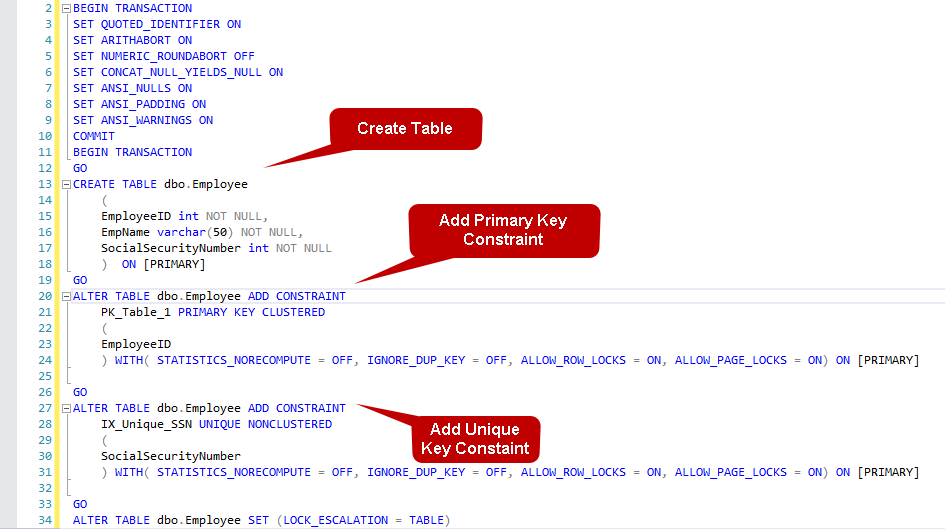
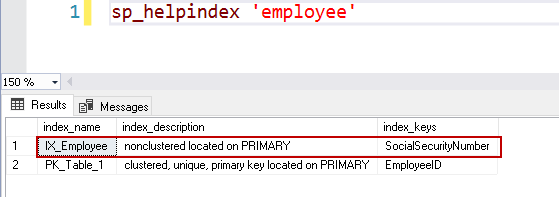
Wykonanie powyższego skryptu, a on utworzy tabelę, klucz główny i ograniczenie klucza unikalnego. Tworzy on indeks SQL Server dla ograniczeń klucza głównego i unikalnego. Możemy sprawdzić istniejące indeksy na tabeli za pomocą systemowej procedury składowanej sys.sp_helpindex.
|
1
2
|
EXEC sys.sp_helpindex @objname = N’Employee'
GO
|

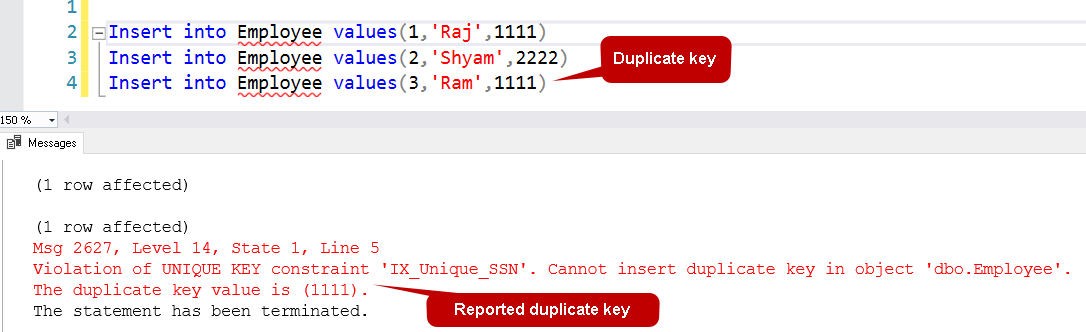
Spróbujmy wstawić kilka wartości do tej tabeli i zobaczmy, czy wolno nam wprowadzić duplikaty w kolumnie.
W poniższym zapytaniu Ram próbuje wprowadzić wartość do kolumny, która jest już dostępna dla pracownika Raj.
|
1
2
3
|
Wstaw do Pracownik values(1,’Raj',1111)
Wstaw do Employee values(2,’Shyam',2222)
Insert into Employee values(3,’Ram',1111)
|
Wstawia pierwsze dwa wiersze pomyślnie, ale dla trzeciego wiersza otrzymujemy komunikat o naruszeniu ograniczenia klucza unikalnego. Otrzymujesz również zduplikowaną wartość w danych wyjściowych. Pomaga to szybko zidentyfikować problematyczne instrukcje wstawiania powodujące problemy.
Wyłączanie ograniczeń unikalnych w SQL Server
Możemy wyłączyć ograniczenie unikalne używając następującej instrukcji ALTER table.
|
1
2
3
|
ALTER TABLE Employee
NOCHECK CONSTRAINT ALL
GO
|
To polecenie zostało wykonane pomyślnie.

Jeśli spróbujemy wprowadzić zduplikowaną wartość, nadal otrzymamy ten sam komunikat o błędzie.

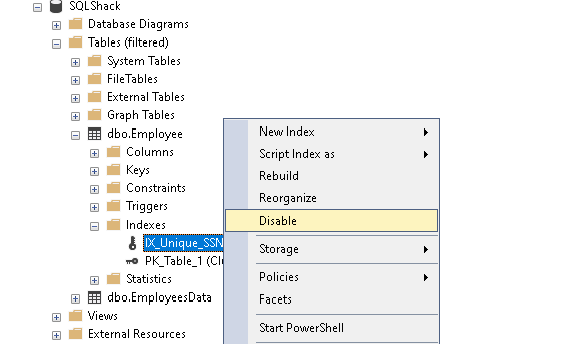
Wiemy, że unikalne ograniczenie w SQL Server tworzy również unikalny indeks SQL Server. SQL Server pozwala nam również na wyłączenie indeksu bez jego upuszczania.
Kliknij prawym przyciskiem myszy na indeksie SQL Server, który chcemy wyłączyć i kliknij na Disable jak pokazano poniżej.
Alternatywnie możemy użyć polecenia ALTER INDEX i wyłączyć indeks serwera SQL. W tym zapytaniu należy podać nazwę indeksu oraz nazwę tabeli.
|
1
2
|
ALTER INDEX IX_Unique_SSN ON Employee
DISABLE
|
Pozwala na wprowadzenie zduplikowanej wartości w kolumnie.
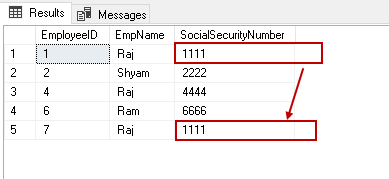
Mamy zduplikowaną wartość w tabeli. Włączmy unikalny indeks nieklastrowany. Aby włączyć Indeks, musimy go przebudować.
Aby przebudować indeks, kliknij prawym przyciskiem myszy na Indeks i wybierz polecenie REBUILD z jego właściwości.
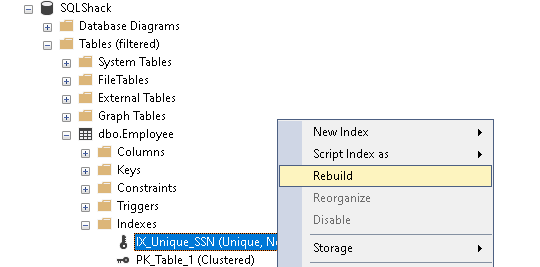
Możemy również przebudować indeks za pomocą poniższego polecenia ALTER INDEX.
|
1
2
3
|
Użyj
GO
ALTER INDEX ON . REBUILD
|
Nie możemy włączyć indeksu, ponieważ istnieje zduplikowany klucz, a ograniczenie unikalnego klucza nie pozwala na duplikaty. Daje to również zduplikowane klucze na wyjściu.
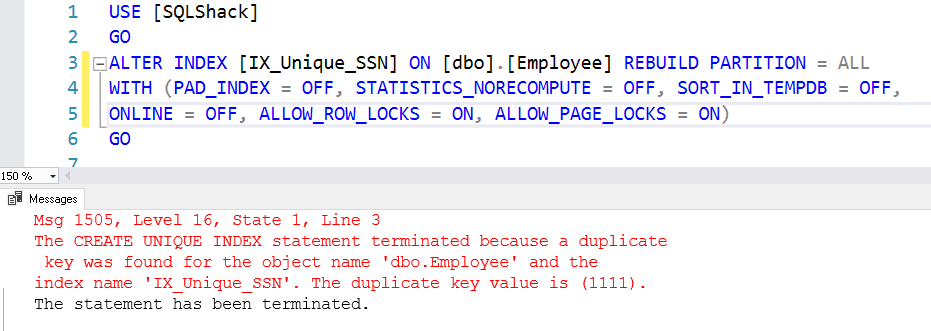
Upuszczanie unikalnych ograniczeń w SQL Server
Nie możemy upuścić unikalnego Indeksu utworzonego przez unikalne ograniczenia. Jeśli próbujemy to zrobić, daje następujący komunikat o błędzie. Nie pozwala on na jawne upuszczenie indeksu, ponieważ unikalne ograniczenie używa indeksu.
|
1
2
|
DROP INDEX Pracownik.
GO
|
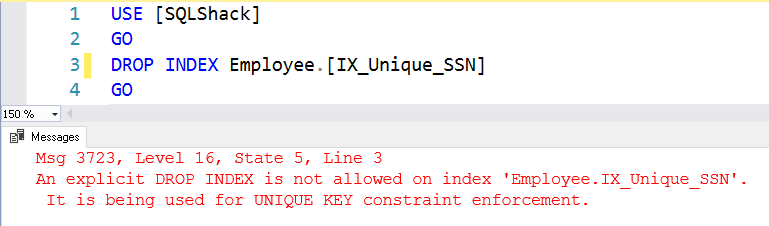
Indeks możemy zrzucić za pomocą polecenia Alter Table Drop Constraint. Jak wiemy, SQL Server tworzy indeks z unikalnym ograniczeniem w SQL Server. To polecenie usuwa indeks wraz z ograniczeniem.
|
1
2
|
ALTER TABLE Pracownik
DROP CONSTRAINT IX_Unique_SSN;
|
Na poniższym zrzucie ekranu możemy zweryfikować, że Indeks nie istnieje obecnie.
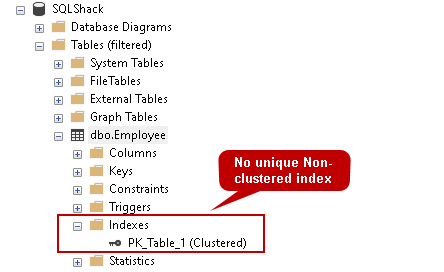
Daje to dodatkową korzyść, że nikt nie może przypadkowo usunąć unikalnego Indeksu utworzonego przez unikalne ograniczenie.
Unikalny indeks w SQL Server
Poprzednio utworzyliśmy unikalne ograniczenia w SQL Server za pomocą metody SSMS GUI. Nie mamy żadnych istniejących unikalnych ograniczeń dla tabeli.
Kliknij prawym przyciskiem myszy na tabelę i wybierz Projekt. Otworzy nam się projekt tabeli, tak jak to widzieliśmy wcześniej.
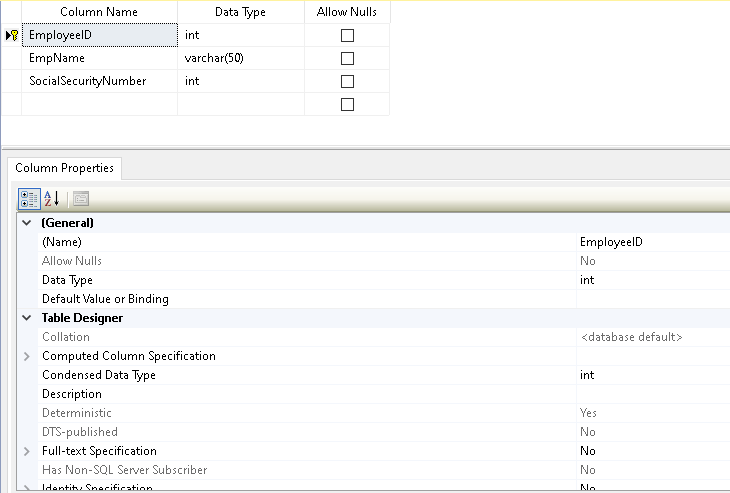
Kliknij prawym przyciskiem myszy na , wybierz Indeks/klucze i wybierz Indeks z kolumny Typ. Dla unikalnego indeksu wybieramy wartość Tak dla kolumny.
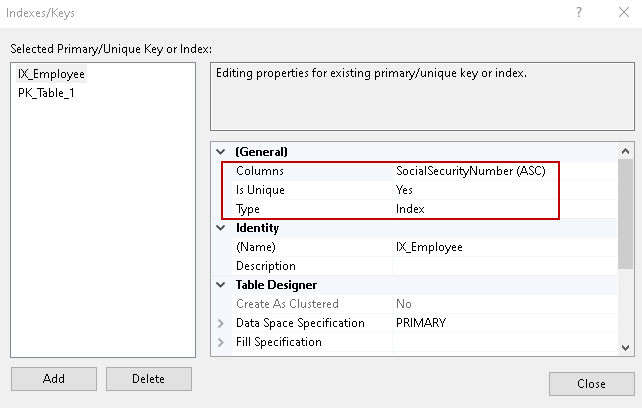
Mamy również włączone kilka opcji dla unikalnych Indeksów takich jak Ignoruj zduplikowane klucze oraz Ponownie oblicz statystyki.
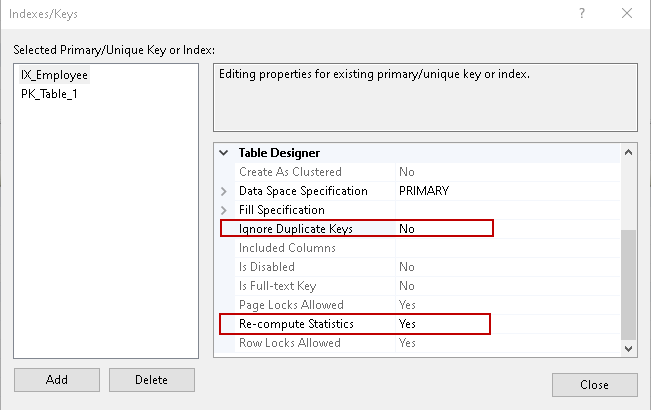
Zamknij stronę indeksu/kluczy i wygeneruj skrypt. Możesz zobaczyć, że tworzy on unikalny indeks nieklastrowy dla tabeli.
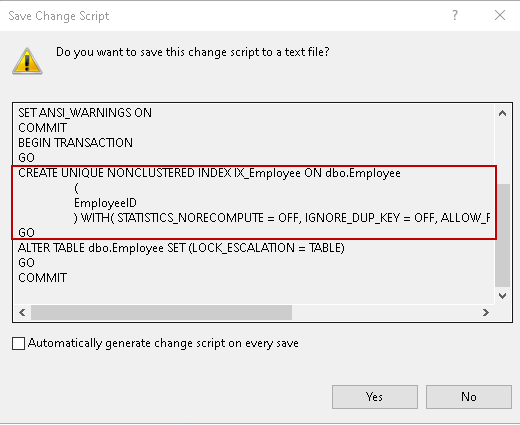
Kliknij Ok i zapisz modyfikacje, które zrobiłeś. Otrzymujesz komunikat o błędzie, ponieważ znalazł duplikat klucza dla kolumny.
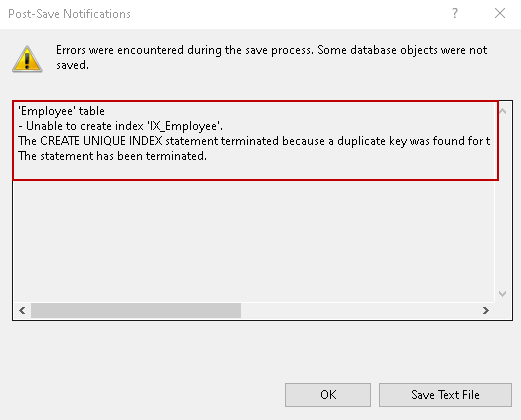
Możemy usunąć duplikat, a to tworzy Indeks dla Ciebie.
Różnica między unikalnymi indeksami a unikalnymi ograniczeniami w SQL Server
Zarówno unikalny indeks jak i unikalne ograniczenie są podobne i nie ma między nimi różnicy funkcjonalnej. Optymalizator zapytań również używa indeksu unikalnego do tworzenia planów wykonania zoptymalizowanych pod względem kosztów. Jedyną różnicą jest to, że nie można bezpośrednio upuścić unikalnego indeksu utworzonego przez unikalne ograniczenie w SQL Server. Otrzymujemy również kilka dodatkowych opcji indeksu po bezpośrednim utworzeniu unikalnego indeksu.
Jak wiemy, ograniczenia są jak reguły biznesowe dla danych przechowywanych w tabelach SQL Server. Powinieneś utworzyć unikalne ograniczenie, gdy nie masz bezpośrednio do czynienia z indeksem. Nie powinieneś jednak definiować unikalnego ograniczenia i klucza dla podobnych kolumn. Może to spowolnić zapytania, a także zduplikować indeksy.

Nie możemy odróżnić unikalnego klucza od indeksu patrząc na indeksy w GUI. Oba istnieją w tym samym folderze indeksów w bazie danych.
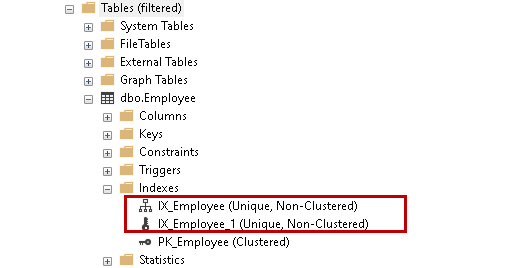
Jednak SQL Server zna różnicę. Jeśli wykonamy skrypt dla obu indeksów, można zobaczyć różne skrypty dla obu indeksów. Jak widzimy poniżej, pierwszy skrypt używa klauzuli alter table with Add Constraint dla unikalnego ograniczenia w SQL Server, podczas gdy późniejsza część używa instrukcji Create Non-Clustered Index.
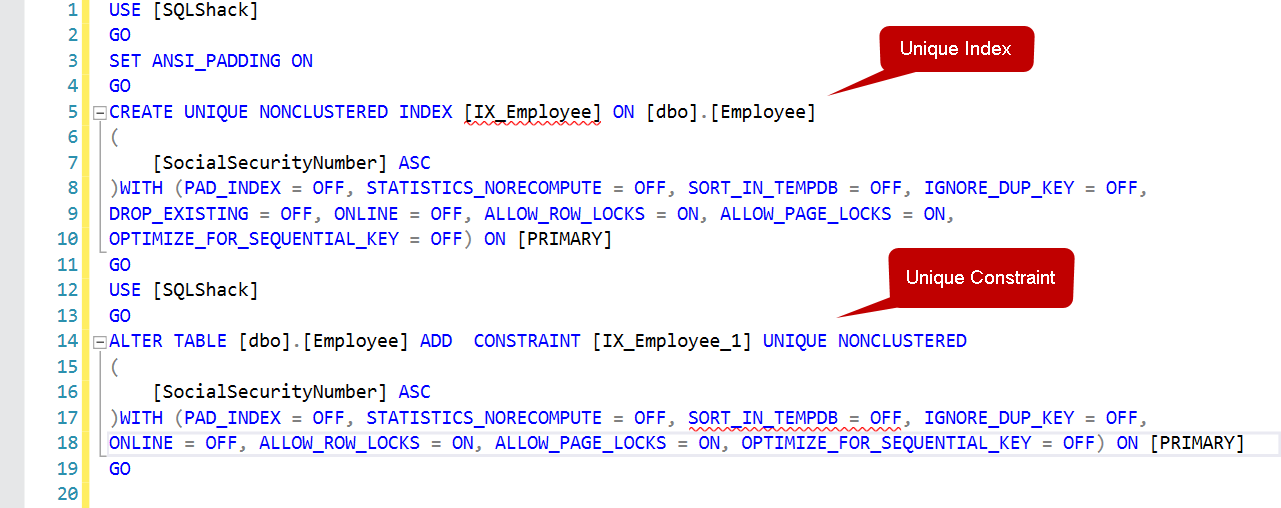
Mimo to, otrzymujesz kilka dodatkowych korzyści z unikalnym indeksem utworzonym jawnie nad Unique Constraints w SQL Server.
- Możesz zawrzeć kolumny w nieklastrowanym unikalnym indeksie, aby poprawić wydajność zapytania. SQL Server wymusza unikalność tylko dla kolumny klucza unikalnego indeksu
- Możemy dodać filtr w unikalnym indeksie. Może to być przydatne, jeśli chcemy utworzyć unikalny indeks na kolumnie, która dopuszcza wartości NULL. W tym przypadku, możemy mieć wiele wartości NULL, ponieważ unikalny indeks zostanie utworzony dla wartości non-null
- Możemy również zdefiniować klucz obcy, który odwołuje się do unikalnego indeksu
Podsumowanie
W tym artykule, zbadaliśmy unikalne ograniczenia i unikalne indeksy w SQL Server. Otrzymujemy unikalny indeks, jeśli tworzymy unikalny warunek. Możesz zdecydować, która opcja będzie dla Ciebie odpowiednia, ponieważ nie ma różnicy w wydajności zapytań.
- Autor
- Recent Posts

Raj jest zawsze zainteresowany nowymi wyzwaniami, więc jeśli potrzebujesz pomocy doradczej na dowolny temat poruszony w jego pismach, można go osiągnąć pod adresem [email protected]
View all posts by Rajendra Gupta
- Konfiguracja długoterminowej retencji kopii zapasowych dla bazy danych Azure SQL – 25 marca, 2021
- Tworzenie spójnej transakcyjnie kopii bazy danych Azure SQL – 22 marca, 2021
- Przegląd Azure Cloud Shell – 18 marca, 2021