W tym artykule przedstawiamy porównanie wydajności poleceń NOT IN, SQL Not Exists, SQL LEFT JOIN oraz SQL EXCEPT.
Biblioteka poleceń T-SQL, dostępna w Microsoft SQL Server i aktualizowana w każdej wersji o nowe polecenia i ulepszenia istniejących poleceń, dostarcza nam różnych sposobów na wykonanie tej samej czynności. Oprócz stale rozwijającego się zestawu poleceń, różni programiści będą stosować różne techniki i podejścia do tych samych zestawów problemów i wyzwań
Na przykład trzech różnych programistów SQL Server może uzyskać te same dane przy użyciu trzech różnych zapytań, przy czym każdy programista ma własne podejście do pisania zapytań T-SQL w celu pobrania lub modyfikacji danych. Ale administrator bazy danych niekoniecznie będzie zadowolony ze wszystkich tych podejść, patrzy na te metody z różnych aspektów, na których mogą się nie skupiać. Chociaż wszystkie z nich mogą uzyskać ten sam wymagany rezultat, każde zapytanie będzie zachowywało się w inny sposób, zużywając inną ilość zasobów serwera SQL z różnym czasem wykonania. Wszystkie te parametry, na których koncentruje się administrator bazy danych, kształtują wydajność zapytania. I to właśnie zasadą administratora bazy danych jest tutaj dostrojenie wydajności tych zapytań i wybranie najlepszej metody z minimalnym możliwym wpływem na ogólną wydajność SQL Server.
W tym artykule opiszemy różne sposoby, które mogą być użyte do pobierania danych z tabeli, które nie istnieją w innej tabeli i porównamy wydajność tych różnych podejść. Metody te będą wykorzystywać polecenia NOT IN, SQL NOT EXISTS, LEFT JOIN i EXCEPT T-SQL. Przed rozpoczęciem porównania wydajności różnych metod, przedstawimy krótki opis każdego z tych poleceń T-SQL.
Polecenie SQL NOT IN pozwala na określenie wielu wartości w klauzuli WHERE. Można je sobie wyobrazić jako serię poleceń NOT EQUAL TO, które są oddzielone warunkiem OR. Polecenie NO IN porównuje określone wartości kolumny z pierwszej tabeli z wartościami innej kolumny w drugiej tabeli lub podzapytaniu i zwraca wszystkie wartości z pierwszej tabeli, które nie występują w drugiej tabeli, bez wykonywania żadnego filtra dla odrębnych wartości. NULL jest traktowany i zwracany przez polecenie NOT IN jako wartość.
Polecenie SQL NOT EXISTS jest używane do sprawdzenia istnienia określonych wartości w podanym podzapytaniu. Podzapytanie nie zwraca żadnych danych; zwraca wartości TRUE lub FALSE w zależności od sprawdzenia istnienia wartości w podzapytaniu.
Polecenie LEFT JOIN jest używane do zwracania wszystkich rekordów z pierwszej lewej tabeli, dopasowanych rekordów z drugiej prawej tabeli oraz wartości NULL z prawej strony dla rekordów z lewej tabeli, które nie mają dopasowania w prawej tabeli.
Polecenie EXCEPT jest używane do zwrócenia wszystkich odrębnych rekordów z pierwszej instrukcji SELECT, które nie zostały zwrócone z drugiej instrukcji SELECT, przy czym każda instrukcja SELECT będzie traktowana jako oddzielny zbiór danych. Innymi słowy, zwraca wszystkie odrębne rekordy z pierwszego zbioru danych i usuwa z tego wyniku rekordy, które są zwracane z drugiego zbioru danych. Można to sobie wyobrazić jako połączenie polecenia SQL NOT EXISTS i klauzuli DISTINCT. Weźmy pod uwagę, że lewy i prawy zbiór danych polecenia EXCEPT powinny mieć taką samą liczbę kolumn.
Zobaczmy teraz w praktyce, jak moglibyśmy pobrać dane z jednej tabeli, które nie istnieją w innej tabeli, używając różnych metod i porównać wydajność tych metod, aby stwierdzić, która z nich zachowuje się najlepiej. Zaczniemy od utworzenia dwóch nowych tabel, używając poniższego skryptu T-SQL:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Cat_Name VARCHAR(50)
O
CREATE TABLE Category_B
( Cat_ID INT ,
Kat_Nazwa VARCHAR(50)
GO
|
Po utworzeniu tabel wypełnimy każdą tabelę 10K rekordami w celach testowych, używając ApexSQL Generate, jak pokazano poniżej:
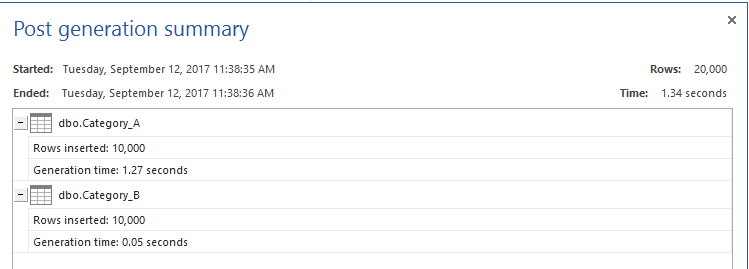
Tabele testowe są już gotowe. Włączymy w nich statystyki TIME i IO, aby wykorzystać je do porównania wydajności różnych metod. Następnie przygotujemy zapytania T-SQL, które posłużą do wyciągnięcia danych, które istnieją w tabeli Category_A, ale nie istnieją w tabeli Category_B za pomocą czterech metod; polecenia NOT IN, polecenia SQL NOT EXISTS, polecenia LEFT JOIN i wreszcie polecenia EXCEPT. Można to osiągnąć za pomocą poniższego skryptu T-SQL:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
UsE SQLShackDemo
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
-.– NOT INT
SELECT Cat_ID
FROM Category_A WHERE Cat_ID NOT IN (SELECT Cat_ID FROM Category_B)
GO
— NOT EXISTS
SELECT A.Cat_ID
FROM Category_A A WHERE NOT EXISTS (SELECT B.Cat_ID FROM Category_B B WHERE B.Cat_ID = A.Cat_ID)
GO
— LEFT JOIN
SELECT A.Cat_ID
FROM Category_A A
LEFT JOIN Category_B B ON A.Cat_ID = B.Cat_ID
WHERE B.Cat_ID IS NULL
GO
— EXCEPT
SELECT A.Cat_ID
FROM Category_A A
EXCEPT
SELECT B.Cat_ID
FROM Category_B B
GO
|
Jeśli wykonasz poprzedni skrypt, przekonasz się, że cztery metody zwrócą ten sam wynik, jak pokazano w poniższym wyniku, który zawiera liczbę zwróconych rekordów przez każde polecenie:
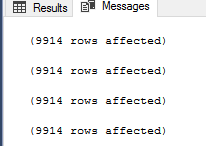
Na tym etapie programista SQL Server będzie zadowolony, ponieważ każda metoda, której użyje, zwróci mu ten sam wynik. Ale co z administratorem bazy danych SQL Server, który musi sprawdzić wydajność każdego z podejść? Jeśli przejrzymy statystyki IO i TIME, które zostały wygenerowane po wykonaniu poprzedniego skryptu, zobaczymy, że skrypt wykorzystujący polecenie NOT IN wykonuje 10062 logiczne odczyty na tabeli Category_B, potrzebuje 228ms na pomyślne zakończenie i 63ms z czasu procesora, jak pokazano poniżej:

Z drugiej strony skrypt, który wykorzystuje polecenie SQL NOT EXISTS wykonuje tylko 29 logicznych odczytów na tabeli Category_B, zajmuje 154ms do pomyślnego zakończenia i 15ms z czasu CPU, co jest znacznie lepsze niż poprzednia metoda, która wykorzystuje NOT IN ze wszystkich aspektów, jak pokazano poniżej:

Dla skryptu wykorzystującego polecenie LEFT JOIN, wykonuje on taką samą liczbę logicznych odczytów jak poprzednia metoda SQL NOT EXISTS, czyli 29 logicznych odczytów, zajmuje 151ms do pomyślnego zakończenia i 16ms od czasu procesora, co jest poniekąd zbliżone do statystyk uzyskanych z poprzedniej metody SQL NOT EXISTS, jak pokazano poniżej:

Na koniec, statystyki wygenerowane po uruchomieniu metody wykorzystującej polecenie EXCEPT pokazują, że wykonuje ona ponownie 29 logicznych odczytów, zajmuje 218ms do pomyślnego zakończenia i zużywa 15ms z czasu procesora, co jest gorsze od metod SQL NOT EXISTS i LEFT JOIN pod względem czasu wykonania, jak pokazano poniżej:

Do tego etapu możemy wywnioskować na podstawie statystyk IO i TIME, że metody wykorzystujące polecenia SQL NOT EXISTS oraz LEFT JOIN działają w najlepszy sposób, z najlepszą ogólną wydajnością. Ale czy plany wykonania zapytań powiedzą nam to samo? Sprawdźmy plany wykonania, które zostały wygenerowane z poprzednich zapytań za pomocą ApexSQL Plan, narzędzia do analizy planów zapytań SQL Server.
Z okna podsumowującego koszty planów wykonania, poniżej, wynika, że metody wykorzystujące polecenia SQL NOT EXISTS oraz LEFT JOIN mają najmniejsze koszty wykonania, natomiast metoda wykorzystująca polecenie NOT IN ma największy koszt wykonania zapytania, jak widać poniżej:

Zanurzmy się głęboko, aby zrozumieć, jak zachowuje się każda metoda, badając plany wykonania dla tych metod.
Plan wykonania dla zapytania, które używa polecenia NOT IN jest złożonym planem z wieloma ciężkimi operatorami, które wykonują pętle i operacje zliczania. To, na czym się tutaj skoncentrujemy, w celu porównania wydajności, to operatory Nested Loops. Pod operatorami zagnieżdżonych pętli, możesz zobaczyć, że te operatory nie są prawdziwymi operatorami złączenia, ale wykonują coś, co nazywa się Left Anti Semi Join. Ten częściowy operator złączenia zwróci wszystkie wiersze z pierwszej lewej tabeli bez pasujących wierszy w drugiej prawej tabeli, pomijając wszystkie pasujące wiersze pomiędzy tymi dwoma tabelami. Najcięższym operatorem w poniższym planie wykonania wygenerowanym przez zapytanie z użyciem polecenia NOT IN jest operator liczenia wierszy, który wykonuje skanowanie nieposortowanej tabeli Category_B, licząc ile wierszy zostało zwróconych i zwraca tylko liczbę wierszy bez żadnych danych, tylko w celu sprawdzenia istnienia wierszy. Plan wykonania będzie wyglądał następująco:
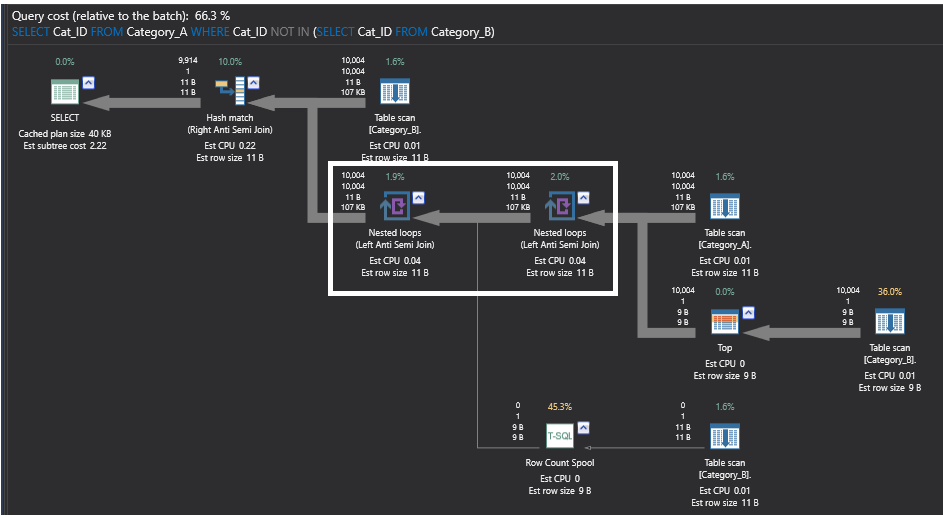
Poniższy plan wykonania, który jest generowany przez zapytanie z użyciem polecenia SQL NOT EXIST jest prostszy od poprzedniego planu, z najcięższym operatorem w tym planie jest operator Hash Match, który ponownie wykonuje operację częściowego złączenia Left Anti Semi Join, która sprawdza istnienie niedopasowanych wierszy, jak opisano wcześniej. Plan ten będzie wyglądał następująco:
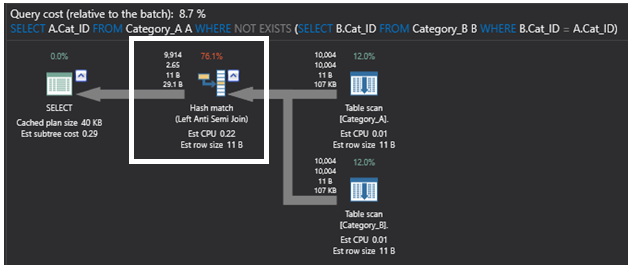
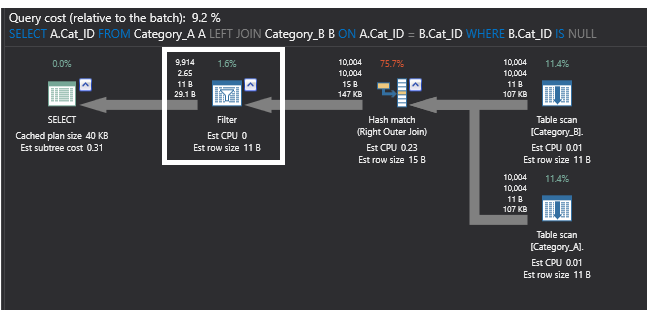
Porównując poprzedni plan wykonania wygenerowany przez zapytanie wykorzystujące polecenie SQL NOT EXISTS z poniższym planem wykonania, który jest wygenerowany przez zapytanie wykorzystujące polecenie LEFT JOIN, nowy plan zastępuje złączenie częściowe operatorem FILTER, który wykonuje filtrowanie IS NULL dla danych zwróconych z operatora Right OUTER JOIN, który zwraca pasujące wiersze z drugiej tabeli, które mogą zawierać duplikaty. Plan ten będzie wyglądał tak, jak pokazano poniżej:
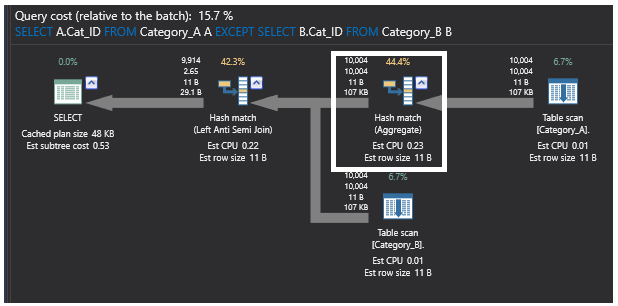
Ostatni plan wykonania wygenerowany przez zapytanie wykorzystujące polecenie EXCEPT zawiera również operację złączenia częściowego Left Anti Semi Join, która sprawdza istnienie niedopasowanych wierszy, jak pokazano wcześniej. Wykonuje również operację Aggregate ze względu na duży rozmiar tabeli i nieposortowane rekordy w niej. Proces Hash Aggregate tworzy tablicę hash w pamięci, co sprawia, że jest to ciężka operacja, a wartość hash zostanie obliczona dla każdego przetwarzanego wiersza i dla każdej obliczonej wartości hash. Następnie sprawdzane są wiersze w wynikowym wiadrze haszującym pod kątem łączących się wierszy. Plan będzie wyglądał tak, jak pokazano poniżej:
Na podstawie poprzednich planów wykonania wygenerowanych przez każde z użytych poleceń możemy ponownie stwierdzić, że najlepsze dwie metody to te wykorzystujące polecenia SQL NOT EXISTS oraz LEFT JOIN. Przypomnijmy, że dane w poprzednich tabelach nie są posortowane ze względu na brak indeksów. Utwórzmy więc indeks na kolumnie łączącej, Cat_ID, w obu tabelach za pomocą poniższego skryptu T-SQL:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Użyj
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
O CREATE NONCLUSTERED INDEX ON .
(
ASC
)
O |
Okno podsumowujące koszty planów wykonania wygenerowane za pomocą ApexSQL Plan po uruchomieniu poprzednich instrukcji SELECT, pokazuje, że metoda wykorzystująca polecenie SQL NOT EXISTS nadal jest najlepsza, a ta wykorzystująca polecenie EXCEPT wyraźnie zyskała po dodaniu indeksów do tabel, jak widać poniżej:

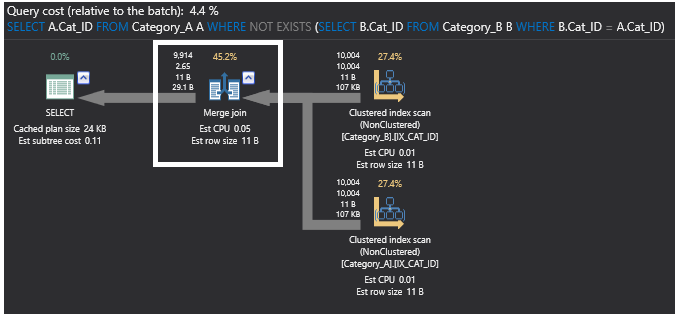
Sprawdzając plan wykonania dla polecenia SQL NOT EXISTS, poprzednia operacja częściowego złączenia została wyeliminowana i zastąpiona operatorem Merge Join, ponieważ dane są teraz posortowane w tabelach po dodaniu indeksów. Nowy plan będzie wyglądał jak na rysunku poniżej:
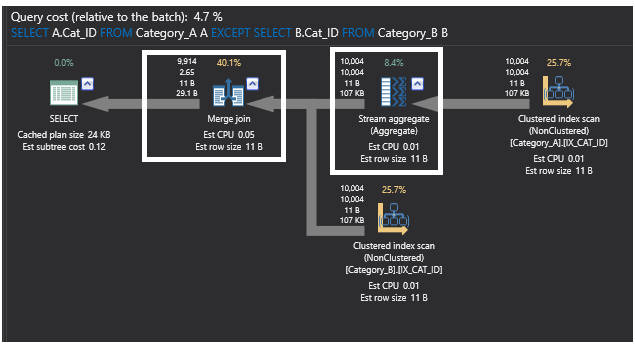
Zapytanie wykorzystujące polecenie EXCEPT wyraźnie wzmocniło się po dodaniu indeksów do tabel i stało się jedną z najlepszych metod do osiągnięcia naszego celu. Pojawiło się to również w poniższym planie wykonania zapytania, w którym poprzednia operacja łączenia częściowego została również zastąpiona operatorem Merge Join, ponieważ dane zostały posortowane poprzez dodanie indeksów. Operator Hash Aggregate został również zastąpiony operatorem Stream Aggregate, gdyż agreguje on posortowane dane po dodaniu indeksów.
Nowy plan będzie wyglądał następująco:
Wnioski:
SQL Server dostarcza nam różnych sposobów na pobranie tych samych danych, pozostawiając deweloperowi SQL Server, aby podążał za swoim własnym podejściem programistycznym, aby to osiągnąć. Na przykład, istnieją różne sposoby, które mogą być użyte do pobierania danych z jednej tabeli, które nie istnieją w innej tabeli. W tym artykule opisaliśmy, jak uzyskać takie dane za pomocą poleceń NOT IN, SQL NOT EXISTS, LEFT JOIN i EXCEPT T-SQL, po przedstawieniu krótkiego opisu każdego polecenia i porównaniu wydajności tych zapytań. Po pierwsze, stwierdzamy, że użycie poleceń SQL NOT EXISTS lub LEFT JOIN jest najlepszym wyborem ze wszystkich aspektów wydajnościowych. Próbowaliśmy również dodać indeks na łączonej kolumnie w obu tabelach, gdzie zapytanie wykorzystujące komendę EXCEPT wyraźnie się poprawiło i wykazało lepszą wydajność, oprócz komendy SQL NOT EXISTS, która nadal jest najlepszym wyborem ogólnie.
Przydatne linki
- EXISTS (Transact-SQL)
- Podkwerendy z EXISTS
- Operatory zestawu – EXCEPT i INTERSECT (Transact-SQL)
- Left Anti Semi Join Showplan Operator
- Autor
- Recent Posts
.

Jest również autorem porad dotyczących SQL na wielu blogach.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers – February 11, 2021
- Jak monitorować Azure Data Factory – 15 stycznia 2021
- Korzystanie z kontroli źródła w Azure Data Factory – 12 stycznia 2021