Dit artikel geeft u een prestatievergelijking voor NOT IN, SQL Not Exists, SQL LEFT JOIN en SQL EXCEPT.
De bibliotheek met T-SQL-commando’s, die beschikbaar is in Microsoft SQL Server en in elke versie wordt bijgewerkt met nieuwe commando’s en uitbreidingen van de bestaande commando’s, biedt ons verschillende manieren om dezelfde actie uit te voeren. Naast een steeds evoluerende toolkit van commando’s, zullen verschillende ontwikkelaars verschillende technieken en benaderingen toepassen op dezelfde probleem sets en uitdagingen
Bijvoorbeeld, drie verschillende SQL Server ontwikkelaars kunnen dezelfde data verkrijgen met behulp van drie verschillende queries, waarbij elke ontwikkelaar zijn eigen aanpak heeft voor het schrijven van de T-SQL queries om de data op te halen of te wijzigen. Maar de database beheerder zal niet noodzakelijk gelukkig zijn met al deze benaderingen, hij bekijkt deze methoden vanuit verschillende aspecten waar zij zich misschien niet op concentreren. Hoewel ze allemaal hetzelfde gewenste resultaat kunnen opleveren, zal elke query zich op een andere manier gedragen, een andere hoeveelheid SQL Server-bronnen verbruiken en andere uitvoeringstijden hebben. Al deze parameters waar de database beheerder zich op concentreert bepalen de performance van de query. En het is de regel van de database beheerder om de performance van deze queries af te stemmen en de beste methode te kiezen met een zo klein mogelijk effect op de algehele SQL Server performance.
In dit artikel zullen we de verschillende manieren beschrijven die gebruikt kunnen worden om gegevens uit een tabel op te halen die niet bestaan in een andere tabel en zullen we de performance van deze verschillende benaderingen vergelijken. Deze methoden zullen gebruik maken van de NOT IN, SQL NOT EXISTS, LEFT JOIN en EXCEPT T-SQL commando’s. Voordat we beginnen met de performance vergelijking tussen de verschillende methoden, zullen we een korte beschrijving geven van elk van deze T-SQL commando’s.
Met het SQL NOT IN commando kunt u meerdere waarden specificeren in de WHERE clause. U kunt het zich voorstellen als een reeks NOT EQUAL TO-commando’s die worden gescheiden door de OR-conditie. Het NO IN commando vergelijkt specifieke kolomwaarden uit de eerste tabel met een andere kolomwaarden in de tweede tabel of een subquery en retourneert alle waarden uit de eerste tabel die niet in de tweede tabel worden gevonden, zonder een filter uit te voeren voor de verschillende waarden. De NULL wordt door het NOT IN commando als waarde beschouwd en teruggegeven.
Het SQL NOT EXISTS commando wordt gebruikt om te controleren op het bestaan van specifieke waarden in de gegeven subquery. De subquery retourneert geen gegevens; het retourneert TRUE of FALSE waarden, afhankelijk van de controle op het bestaan van de subquery-waarden.
Het LEFT JOIN commando wordt gebruikt om alle records van de eerste linker tabel, de overeenkomende records van de tweede rechter tabel en NULL waarden van de rechter kant voor de records van de linker tabel die geen overeenkomst in de rechter tabel hebben, terug te geven.
Het EXCEPT commando wordt gebruikt om alle afzonderlijke records uit de eerste SELECT instructie terug te geven die niet uit de tweede SELECT instructie terugkomen, waarbij elke SELECT instructie als een aparte dataset zal worden beschouwd. Met andere woorden, het retourneert alle afzonderlijke records uit de eerste dataset en verwijdert uit dat resultaat de records die uit de tweede dataset worden geretourneerd. U kunt zich dit voorstellen als een combinatie van het SQL-commando NOT EXISTS en de DISTINCT-clausule. Houd er rekening mee dat de linker en de rechter dataset van het EXCEPT commando hetzelfde aantal kolommen moeten hebben.
Laten we nu eens praktisch bekijken hoe we met verschillende methoden gegevens uit de ene tabel kunnen ophalen die in een andere tabel niet bestaan en de prestaties van deze methoden vergelijken om te concluderen welke zich het beste gedraagt. We zullen beginnen met het maken van twee nieuwe tabellen, met behulp van het onderstaande T-SQL script:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
CREATE TABLE Category_B
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
|
Nadat we de tabellen hebben gemaakt, vullen we elke tabel met 10K records voor testdoeleinden, met behulp van ApexQL Generate, zoals hieronder wordt weergegeven:
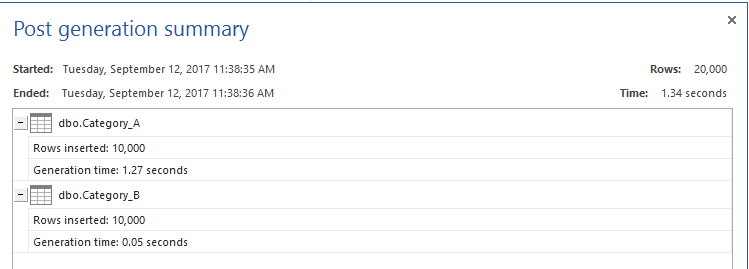
De testtabellen zijn nu klaar. We zullen de TIJD- en IO-statistieken inschakelen om deze statistieken te gebruiken om de prestaties van de verschillende methoden te vergelijken. Daarna bereiden we de T-SQL-query’s voor die worden gebruikt om de gegevens die wel in de tabel Category_A, maar niet in de tabel Category_B voorkomen, op te halen met behulp van vier methoden: het NOT IN-commando, het SQL NOT EXISTS-commando, het LEFT JOIN-commando en ten slotte het EXCEPT-commando. Dit kan worden bereikt met behulp van het onderstaande T-SQL script:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
USE SQLShackDemo
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
— NOT INT
SELECT Cat_ID
FROM Category_A WHERE Cat_ID NOT IN (SELECT Cat_ID FROM Category_B)
GO
— NOT EXISTS
SELECT A.Cat_ID
FROM Category_A A WHERE NOT EXISTS (SELECT B.Cat_ID FROM Category_B B WHERE B.Cat_ID = A.Cat_ID)
GO
— LEFT JOIN
SELECT A.Cat_ID
FROM Category_A A
LEFT JOIN Category_B B ON A.Cat_ID = B.Cat_ID
WHERE B.Cat_ID IS NULL
GO
— EXCEPT
SELECT A.Cat_ID
FROM Category_A A
EXCEPT
SELECT B.Cat_ID
FROM Category_B B
GO
|
Als u het vorige script uitvoert, zult u merken dat de vier methoden hetzelfde resultaat opleveren, zoals te zien is in het onderstaande resultaat dat het aantal geretourneerde records van elk commando bevat:
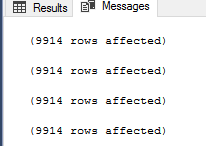
Bij deze stap zal de SQL Server-ontwikkelaar tevreden zijn, omdat elke methode die hij zal gebruiken, hetzelfde resultaat voor hem zal opleveren. Maar hoe zit het met de SQL Server database beheerder die de prestaties van elke aanpak moet controleren? Als we de IO en TIME statistieken bekijken die worden gegenereerd na het uitvoeren van het vorige script, dan zult u zien dat het script dat gebruik maakt van het NOT IN commando 10062 logische reads uitvoert op de Category_B tabel, 228ms nodig heeft om succesvol te worden afgerond en 63ms van de CPU tijd zoals hieronder wordt getoond:

Aan de andere kant voert het script dat het SQL NOT EXISTS-commando gebruikt slechts 29 logische lezingen uit in de Category_B-tabel, duurt het 154 ms om succesvol te worden voltooid en 15 ms van de cpu-tijd, wat in alle opzichten veel beter is dan de vorige methode die NOT IN gebruikt, zoals hieronder te zien is:

Voor het script dat de LEFT JOIN-opdracht gebruikt, voert het hetzelfde aantal logische lezingen uit als de vorige SQL NOT EXISTS-methode, namelijk 29 logische lezingen, die 151 ms nodig hebben om succesvol te worden voltooid en 16 ms van de CPU-tijd, wat enigszins overeenkomt met de statistieken van de vorige SQL NOT EXISTS-methode, zoals hieronder weergegeven:

Ten slotte blijkt uit de statistieken die worden gegenereerd na het uitvoeren van de methode die het EXCEPT-commando gebruikt, dat deze methode opnieuw 29 logische lezingen uitvoert, 218 ms nodig heeft om succesvol te worden voltooid en 15 ms van de CPU-tijd verbruikt, wat slechter is dan de SQL NOT EXISTS- en LEFT JOIN-methoden wat betreft uitvoeringstijd, zoals hieronder wordt weergegeven:

Tot deze stap kunnen we uit de IO en TIME statistieken afleiden dat de methoden die gebruik maken van de SQL NOT EXISTS en LEFT JOIN commando’s het beste werken, met de beste algehele prestaties. Maar zullen de uitvoeringsplannen van de query’s ons hetzelfde resultaat vertellen? Laten we de uitvoeringsplannen controleren die zijn gegenereerd uit de voorgaande queries met ApexSQL Plan, een hulpmiddel voor SQL Server query plan analyse.
Het kostenoverzichtsvenster van de uitvoeringsplannen, hieronder, laat zien dat de methoden die gebruik maken van de SQL NOT EXISTS en de LEFT JOIN commando’s de minste uitvoeringskosten hebben, en dat de methode die gebruik maakt van het NOT IN commando de zwaarste querykosten heeft, zoals hieronder te zien is:

kostenoverzichtsvenster van SQL NOT EXISTS vs LEFT JOIN vs NOT INLaten we eens diep in de materie duiken om te begrijpen hoe elke methode zich gedraagt door de uitvoeringsplannen voor deze methoden te bestuderen.
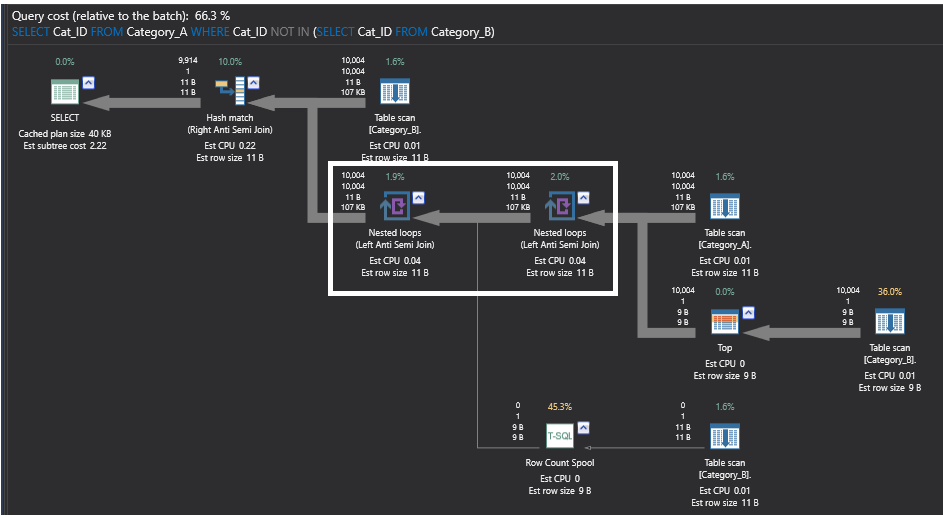
Het uitvoeringsplan voor de query die het NOT IN-commando gebruikt, is een complex plan met een aantal zware operatoren die looping- en teloperaties uitvoeren. Waar we ons hier, ter vergelijking van de prestaties, op zullen concentreren, zijn de Nested Loops operatoren. Onder de Nested Loops operatoren, kun je zien dat deze operatoren geen echte join operatoren zijn, het voert iets uit dat Left Anti Semi Join heet. Deze gedeeltelijke join operator retourneert alle rijen uit de eerste linker tabel met geen overeenkomende rijen in de tweede rechter tabel, waarbij alle overeenkomende rijen tussen de twee tabellen worden overgeslagen. De zwaarste operator in het onderstaande uitvoeringsplan dat gegenereerd wordt door de query die gebruik maakt van het NOT IN commando is de Row Count Spool operator, die scans uitvoert op de ongesorteerde Category_B tabel, telt hoeveel rijen er terugkomen, en alleen het aantal rijen teruggeeft zonder enige data, alleen voor rijen-bestaanscontrole doeleinden. Het uitvoeringsplan ziet er als volgt uit:
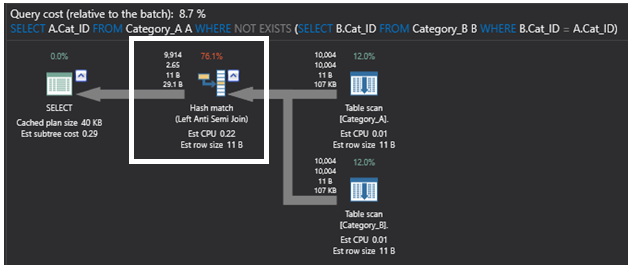
Het onderstaande uitvoeringsplan dat wordt gegenereerd door de query met behulp van het SQL NOT EXIST commando is eenvoudiger dan het vorige plan, met de zwaarste operator in dat plan is de Hash Match operator die opnieuw een Left Anti Semi Join partiële join operatie uitvoert die controleert op niet gematchte rijen bestaan zoals eerder beschreven. Dit plan ziet er als volgt uit:
Vergelijking van het vorige uitvoeringsplan dat is gegenereerd door de query die gebruik maakt van het SQL NOT EXISTS commando met het onderstaande uitvoeringsplan dat is gegenereerd door de query die gebruik maakt van het LEFT JOIN commando, het nieuwe plan vervangt de gedeeltelijke join door een FILTER operator die de IS NULL filtering uitvoert voor de gegevens die terugkomen van de Right OUTER JOIN operator, die de overeenkomende rijen teruggeeft uit de tweede tabel die duplicaten kan bevatten. Het plan ziet er dan uit als hieronder:
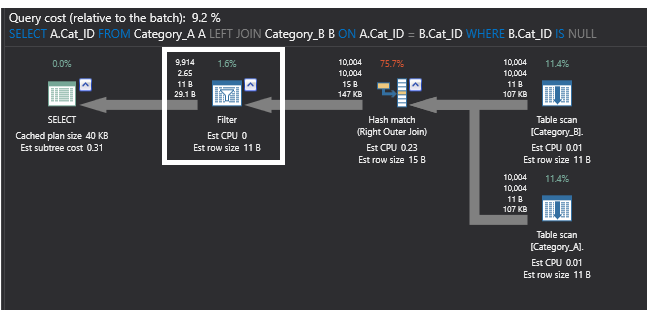
Het laatste uitvoeringsplan dat wordt gegenereerd door de query die het EXCEPT commando gebruikt bevat ook de Left Anti Semi Join partial join operatie die controleert op het bestaan van ongeëvenaarde rijen zoals eerder getoond. Het voert ook een Aggregate operatie uit vanwege de grote omvang van de tabel en de ongesorteerde records in de tabel. Het Hash Aggregate proces maakt een hashtabel aan in het geheugen, wat het een zware operatie maakt, en voor elke verwerkte rij en voor elke berekende hashwaarde wordt een hashwaarde berekend. Daarna controleert het de rijen in de resulterende hash bucket voor de samenkomende rijen. Het plan ziet er dan uit als hieronder:
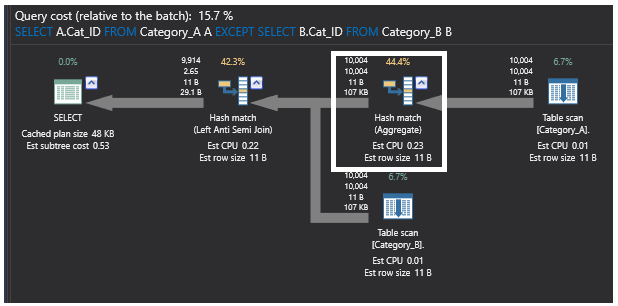
Uit de vorige uitvoeringsplannen die door elk gebruikt commando zijn gegenereerd, kunnen we opnieuw concluderen dat de beste twee methoden die zijn waarbij gebruik wordt gemaakt van de SQL NOT EXISTS- en LEFT JOIN-commando’s. Vergeet niet dat de gegevens in de vorige tabellen niet gesorteerd zijn door het ontbreken van de indexen. Laten we dus een index maken op de samenvoeg kolom, de Cat_ID, in beide tabellen met behulp van het onderstaande T-SQL script:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
USE
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
GO
|
Het kostenoverzichtsvenster van de uitvoeringsplannen, gegenereerd met ApexSQL Plan na het uitvoeren van de vorige SELECT-statements, laat zien dat de methode die gebruik maakt van het SQL NOT EXISTS commando nog steeds de beste is en de methode die gebruik maakt van het EXCEPT commando duidelijk verbeterd na het toevoegen van de indexen aan de tabellen, zoals hieronder te zien is:

Als je het uitvoeringsplan voor het SQL NOT EXISTS commando bekijkt, wordt de vorige partiële join operatie nu geëlimineerd en vervangen door de Merge Join operator, omdat de gegevens nu gesorteerd zijn in de tabellen na het toevoegen van de indexen. Het nieuwe plan ziet er dan uit zoals hieronder:
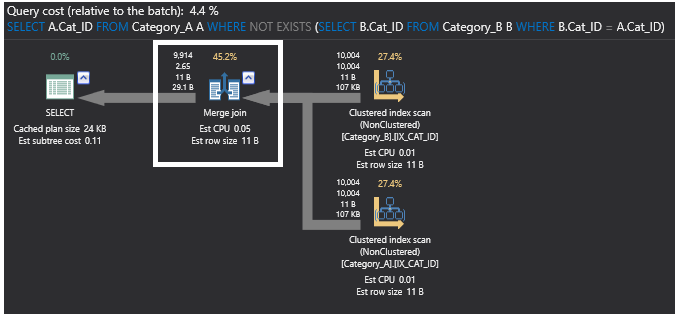
De query die gebruik maakt van het EXCEPT commando verbeterde duidelijk na het toevoegen van de indexen aan de tabellen en werd een van de beste methodes om ons doel hier te bereiken. Dit blijkt ook uit het onderstaande query uitvoeringsplan, waarin de vorige partiële join operatie ook is vervangen door de Merge Join operator, omdat de gegevens zijn gesorteerd door het toevoegen van de indexen. De Hash Aggregate operator is nu ook vervangen door een Stream Aggregate operator, omdat deze een gesorteerde data aggregeert na het toevoegen van de indexen.
Het nieuwe plan ziet er als volgt uit:
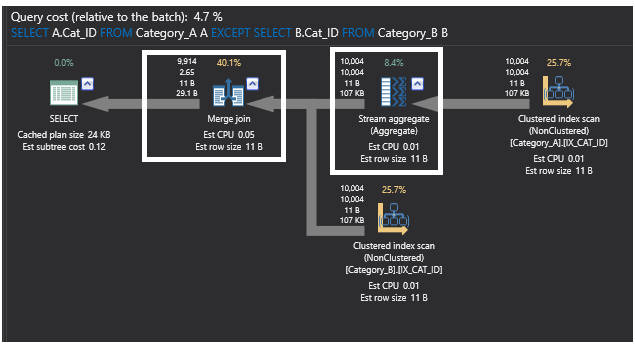
Conclusie:
SQL Server biedt ons verschillende manieren om dezelfde gegevens op te halen, waarbij het aan de SQL Server ontwikkelaar wordt overgelaten om zijn eigen ontwikkelaanpak te volgen om dat te bereiken. Er zijn bijvoorbeeld verschillende manieren om gegevens uit een tabel op te halen die in een andere tabel niet bestaan. In dit artikel hebben we beschreven hoe dergelijke gegevens kunnen worden opgehaald met behulp van NOT IN, SQL NOT EXISTS, LEFT JOIN en EXCEPT T-SQL commando’s, nadat we een korte beschrijving van elk commando hebben gegeven en de prestaties van deze queries hebben vergeleken. We concluderen ten eerste dat het gebruik van de SQL NOT EXISTS of de LEFT JOIN commando’s de beste keuze is vanuit alle prestatie-aspecten. We hebben ook geprobeerd een index toe te voegen op de samenvoeg kolom in beide tabellen, waarbij de query die gebruik maakt van het EXCEPT commando duidelijk verbeterde en betere prestaties liet zien, naast het SQL NOT EXISTS commando dat over het algemeen nog steeds de beste keuze is.
Nuttige links
- EXISTS (Transact-SQL)
- Subquery’s met EXISTS
- Set Operators – EXCEPT en INTERSECT (Transact-SQL)
- Left Anti Semi Join Showplan Operator
- Auteur
- Recent Posts

Hij is Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate en Microsoft Certified Trainer.
Ook levert hij bijdragen met zijn SQL tips in vele blogs.
Bekijk alle berichten van Ahmad Yaseen
- Azure Data Factory Interview Vragen en Antwoorden – 11 februari, 2021
- Hoe Azure Data Factory te monitoren – 15 januari 2021
- Source Control gebruiken in Azure Data Factory – 12 januari 2021