この記事では、NOT IN、SQL Not Exists、SQL LEFT JOIN、SQL EXCEPTのパフォーマンス比較を紹介します。
Microsoft SQL Serverに搭載されているT-SQLコマンドライブラリは、バージョンが上がるごとに新しいコマンドや既存のコマンドの拡張が行われており、同じ動作を行うためのさまざまな方法を提供しています。 進化し続けるコマンドのツールキットに加えて、異なる開発者は、同じ問題セットや課題に対して、異なる技術やアプローチを適用します
例えば、3人の異なるSQL Server開発者は、3つの異なるクエリを使用して同じデータを取得することができ、各開発者はデータを取得または修正するためのT-SQLクエリを書くために独自のアプローチを持っています。 しかし、データベース管理者は、必ずしもこれらのアプローチのすべてに満足しているわけではありません。データベース管理者は、彼らが集中していない異なる側面からこれらの方法を見ています。 これらの方法はすべて同じ結果を得ることができるかもしれませんが、それぞれのクエリは異なる方法で動作し、異なる量のSQL Serverリソースを消費し、異なる実行時間を持つことになります。 データベース管理者が集中的に取り組むこれらすべてのパラメータが、クエリのパフォーマンスを形成します。
この記事では、別のテーブルに存在しないデータをテーブルから取得するために使用できるさまざまな方法を説明し、これらの異なるアプローチのパフォーマンスを比較します。 これらの方法は、NOT IN、SQL NOT EXISTS、LEFT JOIN、EXCEPTのT-SQLコマンドを使用します。
SQL NOT INコマンドは、WHERE句に複数の値を指定することができます。 これは、OR条件で区切られた一連のNOT EQUAL TOコマンドと想像できます。 NO INコマンドは、第1テーブルの特定の列の値と、第2テーブルまたはサブクエリの別の列の値を比較し、第1テーブルの値のうち、第2テーブルにないすべての値を、別個の値に対するフィルタを実行せずに返します。 NULLはNOT INコマンドによって値として考慮され、返されます。
SQL NOT EXISTSコマンドは、指定された副問い合わせの中に特定の値が存在するかどうかを確認するために使用されます。
LEFT JOINコマンドは、最初の左テーブルからすべてのレコードを返し、2番目の右テーブルからマッチしたレコードを返し、右テーブルでマッチしない左テーブルのレコードに対しては、右からNULL値を返すために使用されます。
EXCEPTコマンドは、最初のSELECT文から、2番目のSELECT文から返されないすべての個別のレコードを返すために使用され、各SELECT文は個別のデータセットとみなされます。 つまり、最初のデータセットからすべてのレコードを返し、その結果から2番目のデータセットから返されたレコードを削除するのです。 SQLのNOT EXISTSコマンドとDISTINCT句を組み合わせたものと想像できます。
では、あるテーブルから別のテーブルに存在しないデータを、異なる方法で取得する方法を実際に見て、その性能を比較し、どの方法が一番良いかを結論付けましょう。 まず、以下のT-SQLスクリプトを使用して、2つの新しいテーブルを作成します。
|
1
2
3
4div
5
6
7
8
9
10
11
12
|
iv
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
CREATE TABLE Category_B
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
|
テーブルを作成した後、以下のようにApexSQL Generateを使用して、テスト用に各テーブルに10Kレコードを充填します。
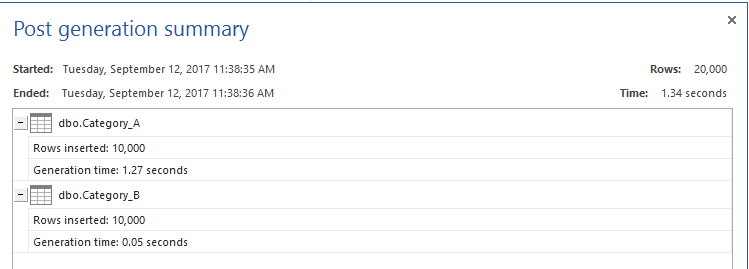
これでテスト用テーブルの準備が整いました。 TIME統計とIO統計を有効にして、これらの統計を使って異なる方法のパフォーマンスを比較します。 その後、NOT INコマンド、SQL NOT EXISTSコマンド、LEFT JOINコマンド、EXCEPTコマンドの4つの方法を使用して、Category_Aテーブルには存在するが、Category_Bテーブルには存在しないデータを引き出すために使用するT-SQLクエリを準備します。 これは、以下のT-SQLスクリプトで実現できます。
|
1
2
3
4
5
6div
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
です。 30
|
USE SQLShackDemo
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
-。– NOT INT
SELECT Cat_ID
FROM Category_A WHERE Cat_ID NOT IN (SELECT Cat_ID FROM Category_B)
GO
— NOT EXISTS
SELECT A.Cat_ID
FROM Category_A A WHERE NOT EXISTS (SELECT B.Cat_ID FROM Category_B B WHERE B.Cat_ID = A.Cat_ID)
GO
— LEFT JOIN
SELECT A.Cat_ID
FROM Category_A A
LEFT JOIN Category_B B ON A.Cat_ID = B.Cat_ID
WHERE B.Cat_ID IS NULL
GO
— EXCEPT
SELECT A.Cat_ID
FROM Category_A A
EXCEPT
SELECT B.Cat_ID
FROM Category_B B
GO
|
先ほどのスクリプトを実行すると、各コマンドで返されたレコードの数を含む以下の結果のように、4つのメソッドが同じ結果を返すことが分かります。
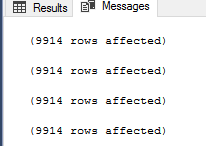
この段階で、SQL Serverの開発者は、どの方法を使っても同じ結果が得られるので満足するでしょう。 しかし、各手法のパフォーマンスをチェックする必要のあるSQL Serverデータベース管理者はどうでしょうか? 前述のスクリプトを実行した後に生成されたIOとTIMEの統計を見てみると、NOT INコマンドを使用したスクリプトでは、以下のようにCategory_Bテーブルに対して10062回の論理的読み取りを行い、正常に完了するまでに228msかかり、CPUタイムは63msであることがわかります。

一方、SQL NOT EXISTSコマンドを使用したスクリプトでは、以下のように、Category_Bテーブルに対して29回の論理的読み取りを行うだけで、正常に完了するまでに154ms、CPU時間で15msかかり、NOT INを使用した以前の方法よりも、あらゆる面ではるかに優れています。

LEFT JOIN コマンドを使用するスクリプトでは、以前の SQL NOT EXISTS メソッドと同じ数の論理的読み取りを実行しますが、その数は 29 論理的読み取りで、正常に完了するまでに 151ms かかり、CPU 時間は 16ms でした。
最後に、EXCEPT コマンドを使用するメソッドを実行した後に生成された統計では、再び 29 の論理的読み取りを行い、正常に完了するまでに 218ms かかり、CPU 時間を 15ms 消費します。

この段階までは、IOとTIMEの統計から、SQL NOT EXISTSとLEFT JOINコマンドを使用する方法が、全体的なパフォーマンスが最も良い方法で動作していることを導き出すことができます。 しかし、クエリの実行計画でも同じ結果になるのでしょうか? SQL Serverのクエリプラン解析ツールであるApexSQL Planを使って、前のクエリから生成された実行プランを確認してみましょう。
下の実行計画コストサマリーウィンドウでは、SQL NOT EXISTSコマンドとLEFT JOINコマンドを使用した方法が最も実行コストが少なく、NOT INコマンドを使用した方法が最も重いクエリコストであることが示されています。

これらのメソッドの実行プランを調べることで、各メソッドがどのように動作するかを深く理解しましょう。
NOT IN コマンドを使用するクエリの実行プランは、ループ処理やカウント処理を行う多くの重い演算子を含む複雑なプランです。 ここでは、パフォーマンス比較のために、Nested Loops 演算子に注目します。 Nested Loops演算子では、これらの演算子が実際の結合演算子ではなく、Left Anti Semi Joinと呼ばれるものを実行していることがわかります。 この部分的結合演算子は、最初の左のテーブルから、2番目の右のテーブルで一致する行がないすべての行を返し、2つのテーブル間で一致するすべての行をスキップします。 この演算子は、ソートされていないCategory_Bテーブルに対してスキャンを実行し、返された行数を数え、行の存在を確認する目的のみで、データを含まない行数のみを返します。 実行計画は以下のようになります。
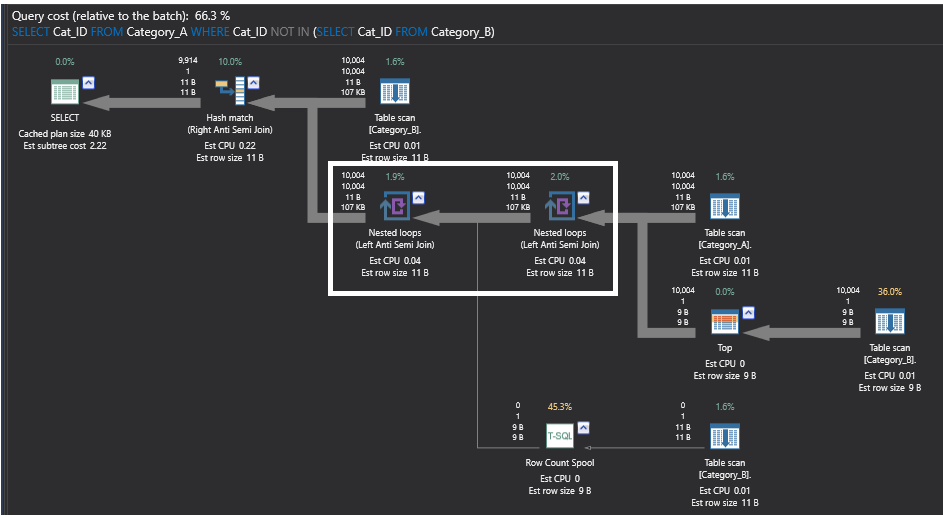
以下の実行プランは、SQL NOT EXISTコマンドを使用したクエリによって生成されたもので、前のプランよりもシンプルになっています。 このプランで最も重い演算子はHash Match演算子で、前述のようにマッチしていない行の存在をチェックするLeft Anti Semi Join部分結合演算を再び実行します。 このプランは以下のようになります。
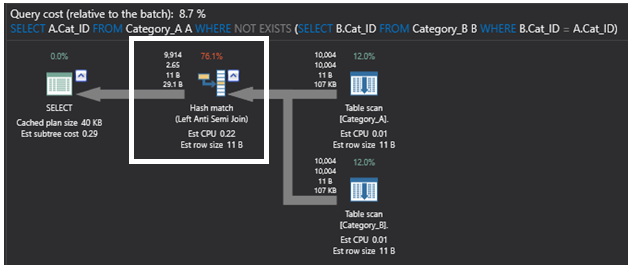
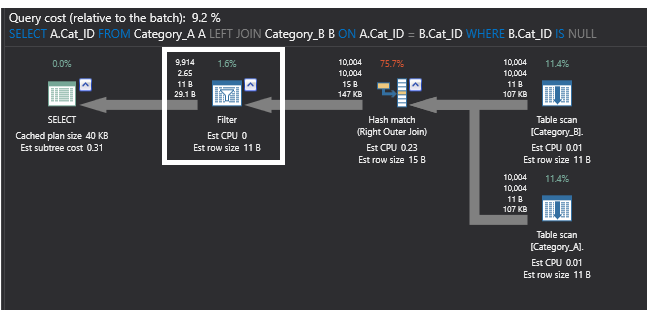
SQL NOT EXISTS コマンドを使用するクエリによって生成された以前の実行プランと、LEFT JOIN コマンドを使用するクエリによって生成された以下の実行プランを比較しています。 新しいプランでは、部分結合をFILTER演算子に置き換え、右外部結合演算子から返されたデータに対してIS NULLフィルタリングを行い、重複している可能性のある2番目のテーブルから一致する行を返します。 この計画は以下のようになります。
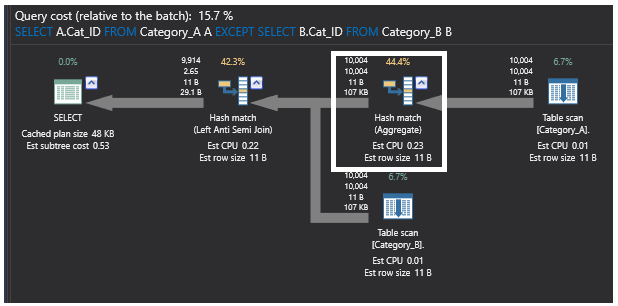
EXCEPTコマンドを使用したクエリによって生成された最後の実行プランには、先に示したように、マッチしていない行の存在をチェックするLeft Anti Semi Join部分結合操作も含まれています。 また、テーブルのサイズが大きく、ソートされていないレコードがあるため、Aggregateオペレーションも実行されます。 Hash Aggregate処理では、メモリ内にハッシュテーブルを作成するため、重い処理となり、処理された行ごとに、また計算されたハッシュ値ごとに、ハッシュ値が計算されます。 その後、結果として得られるハッシュバケット内の行をチェックして、結合する行を探します。 プランは以下のようになります。
使用した各コマンドで生成された以前の実行プランから、SQL NOT EXISTS コマンドと LEFT JOIN コマンドを使用した 2 つの方法が最適であると再度結論づけることができます。 前のテーブルのデータは、インデックスがないためにソートされていないことを思い出してください。 そこで、以下のT-SQLスクリプトを使って、両方のテーブルに結合列であるCat_IDにインデックスを作成してみましょう。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
USE
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
GO
|
以前のSELECT文を実行した後、ApexSQL Planを使って生成された実行計画コストのサマリーウィンドウです。 以下に示すように、SQL NOT EXISTS コマンドを使用する方法が依然として最良であり、EXCEPT コマンドを使用する方法は、テーブルにインデックスを追加した後に明らかに強化されたことを示しています。

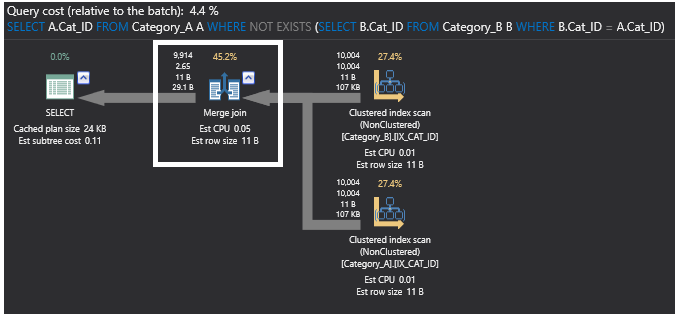
SQL NOT EXISTSコマンドの実行プランを確認すると、インデックスを追加した後のテーブルではデータがソートされているため、以前の部分結合操作は削除され、Merge Join演算子に置き換えられています。 新しいプランは以下のようになります。
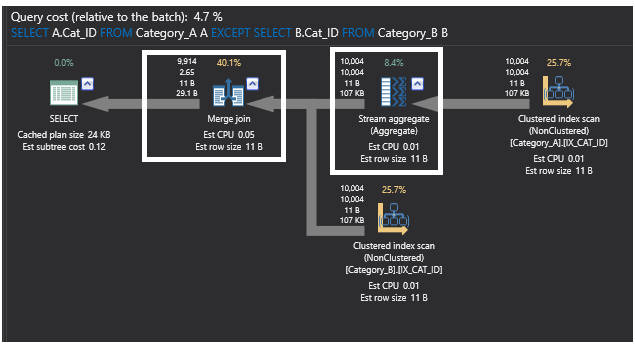
EXCEPTコマンドを使用したクエリは、テーブルにインデックスを追加した後に明らかに強化され、今回の目的を達成するための最良の方法の1つとなりました。 これは以下のクエリ実行プランにも現れており、インデックスを追加することでデータがソートされるため、以前の部分的な結合操作もMerge Join演算子に置き換えられています。 また、インデックスを追加してソートされたデータを集約するため、Hash Aggregate 演算子も Stream Aggregate 演算子に置き換えられています。
新しいプランは以下のようになります。
結論です。
SQL Server は、同じデータを取得するためのさまざまな方法を提供してくれますが、それを実現するためには、SQL Server の開発者が独自の開発アプローチに従う必要があります。 たとえば、あるテーブルから別のテーブルに存在しないデータを取り出すためには、さまざまな方法があります。 この記事では、NOT IN、SQL NOT EXISTS、LEFT JOIN、EXCEPTのT-SQLコマンドを使ってそのようなデータを取得する方法を、それぞれのコマンドの簡単な説明の後、これらのクエリのパフォーマンスを比較しながら説明しました。 結論としては、まず、SQL NOT EXISTSやLEFT JOINコマンドを使用することが、すべての性能面で最良の選択であることがわかりました。 また、両方のテーブルの結合カラムにインデックスを追加してみましたが、SQL NOT EXISTS コマンドが全体的に最良の選択であることに加えて、EXCEPT コマンドを使用したクエリが明らかに強化され、より良いパフォーマンスを示しました。
お役立ちリンク集
- EXISTS (Transact-SQL)
- EXISTS を使用したサブクエリ
- Set Operators – EXCEPT and INTERSECT (Transact-SQL)
- EXCEPT コマンドを使用したクエリは明らかにパフォーマンスが向上しました。SQL)
- 左アンチセミジョインションプラン演算子
- 著者
- 最近の投稿
です。

また、多くのブログでSQLに関するヒントを提供しています。
Ahmad Yaseenの全投稿を見る
- Azure Data Factory Interview Questions and Answers – February 11, 2021年
- Azure Data Factoryを監視する方法 – 2021年1月15日
- Azure Data Factoryでソースコントロールを使用する – 2021年1月12日