Questo articolo fornisce un confronto delle prestazioni per NOT IN, SQL Not Exists, SQL LEFT JOIN e SQL EXCEPT.
La libreria di comandi T-SQL, disponibile in Microsoft SQL Server e aggiornata in ogni versione con nuovi comandi e miglioramenti ai comandi esistenti, ci fornisce diversi modi per eseguire la stessa azione. Oltre a un toolkit di comandi in continua evoluzione, sviluppatori diversi applicheranno tecniche e approcci diversi agli stessi problemi e sfide
Per esempio, tre diversi sviluppatori di SQL Server possono ottenere gli stessi dati usando tre query diverse, e ogni sviluppatore ha il suo approccio per scrivere le query T-SQL per recuperare o modificare i dati. Ma l’amministratore del database non sarà necessariamente contento di tutti questi approcci, sta guardando a questi metodi da aspetti diversi su cui potrebbero non concentrarsi. Anche se tutti possono ottenere lo stesso risultato richiesto, ogni query si comporta in modo diverso, consuma una quantità diversa di risorse di SQL Server con tempi di esecuzione diversi. Tutti questi parametri su cui l’amministratore del database si concentra modellano le prestazioni della query. Ed è la regola dell’amministratore di database qui per sintonizzare le prestazioni di queste query e scegliere il metodo migliore con il minimo effetto possibile sulle prestazioni generali di SQL Server.
In questo articolo, descriveremo i diversi modi che possono essere utilizzati per recuperare i dati da una tabella che non esiste in un’altra tabella e confrontare le prestazioni di questi diversi approcci. Questi metodi useranno i comandi T-SQL NOT IN, SQL NOT EXISTS, LEFT JOIN e EXCEPT. Prima di iniziare il confronto delle prestazioni tra i diversi metodi, forniremo una breve descrizione di ognuno di questi comandi T-SQL.
Il comando SQL NOT IN permette di specificare più valori nella clausola WHERE. Potete immaginarlo come una serie di comandi NOT EQUAL TO separati dalla condizione OR. Il comando NO IN confronta i valori di una specifica colonna della prima tabella con i valori di un’altra colonna nella seconda tabella o con una sottoquery e restituisce tutti i valori della prima tabella che non si trovano nella seconda tabella, senza eseguire alcun filtro per i valori distinti. Il NULL viene considerato e restituito dal comando NOT IN come un valore.
Il comando SQL NOT EXISTS viene utilizzato per verificare l’esistenza di valori specifici nella subquery fornita. La sottoquery non restituisce alcun dato; restituisce valori VERO o FALSO a seconda del controllo dell’esistenza dei valori della sottoquery.
Il comando LEFT JOIN è usato per restituire tutti i record della prima tabella di sinistra, i record corrispondenti della seconda tabella di destra e valori NULL dalla parte destra per i record della tabella di sinistra che non hanno corrispondenza nella tabella di destra.
Il comando EXCEPT è usato per restituire tutti i record distinti dalla prima istruzione SELECT che non sono restituiti dalla seconda istruzione SELECT, con ogni istruzione SELECT sarà considerata come un set di dati separato. In altre parole, restituisce tutti i record distinti dal primo set di dati e rimuove da quel risultato i record che vengono restituiti dal secondo set di dati. Potete immaginarlo come una combinazione del comando SQL NOT EXISTS e della clausola DISTINCT. Prendete in considerazione che il set di dati di sinistra e quello di destra del comando EXCEPT devono avere lo stesso numero di colonne.
Ora, vediamo, in termini pratici, come possiamo recuperare i dati da una tabella che non esistono in un’altra tabella usando diversi metodi e confrontiamo le prestazioni di questi metodi per concludere quale si comporta nel modo migliore. Inizieremo creando due nuove tabelle, usando lo script T-SQL qui sotto:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
CREARE TABLE Category_B
( Cat_ID INT ,
Cat_Name VARCHAR(50)
)
GO
|
Dopo aver creato le tabelle, riempiremo ogni tabella con 10K record a scopo di test, utilizzando ApexSQL Generate come mostrato di seguito:
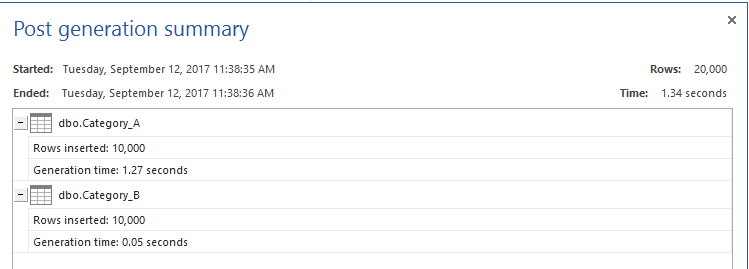
Le tabelle di test sono ora pronte. Abiliteremo le statistiche TIME e IO per utilizzare queste statistiche per confrontare le prestazioni dei diversi metodi. Dopo di che prepareremo le query T-SQL che sono usate per estrarre i dati che esistono nella tabella Category_A ma non esistono nella tabella Category_B usando quattro metodi; comando NOT IN, comando SQL NOT EXISTS, comando LEFT JOIN e infine comando EXCEPT. Questo può essere ottenuto usando lo script T-SQL qui sotto:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
USE SQLShackDemo
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
— NOT INT
SELECT Cat_ID
FROM Category_A WHERE Cat_ID NOT IN (SELECT Cat_ID FROM Category_B)
GO
— NOT EXISTS
SELECT A.Cat_ID
FROM Category_A A WHERE NOT EXISTS (SELECT B.Cat_ID FROM Category_B B WHERE B.Cat_ID = A.Cat_ID)
GO
— LEFT JOIN
SELECT A.Cat_ID
FROM Category_A A
LEFT JOIN Category_B B ON A.Cat_ID = B.Cat_ID
WHERE B.Cat_ID IS NULL
GO
— EXCEPT
SELECT A.Cat_ID
FROM Category_A A
EXCEPT
SELECT B.Cat_ID
FROM Category_B B
GO
|
Se si esegue lo script precedente, si scopre che i quattro metodi restituiscono lo stesso risultato, come mostrato nel risultato sottostante che contiene il numero di record restituiti da ogni comando:
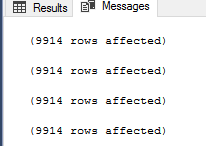
A questo punto, lo sviluppatore di SQL Server sarà contento, poiché qualsiasi metodo userà, gli restituirà lo stesso risultato. Ma che dire dell’amministratore del database di SQL Server che ha bisogno di controllare le prestazioni di ogni approccio? Se esaminiamo le statistiche IO e TIME che vengono generate dopo l’esecuzione dello script precedente, vedrete che lo script che usa il comando NOT IN esegue 10062 letture logiche sulla tabella Category_B, impiega 228ms per essere completato con successo e 63ms dal tempo della CPU come mostrato sotto:

D’altra parte, lo script che usa il comando SQL NOT EXISTS esegue solo 29 letture logiche sulla tabella Category_B, impiega 154ms per essere completato con successo e 15ms dal tempo della CPU, che è molto meglio del metodo precedente che usa NOT IN da tutti gli aspetti, come mostrato sotto:

Per lo script che usa il comando LEFT JOIN, esegue lo stesso numero di letture logiche del precedente metodo SQL NOT EXISTS, cioè 29 letture logiche, impiega 151ms per essere completato con successo e 16ms dal tempo della CPU, che è in qualche modo simile alle statistiche derivate dal precedente metodo SQL NOT EXISTS, come mostrato sotto:

Infine, le statistiche generate dopo l’esecuzione del metodo che usa il comando EXCEPT mostrano che esegue di nuovo 29 letture logiche, impiega 218ms per essere completato con successo, e consuma 15ms dal tempo della CPU, che è peggio dei metodi SQL NOT EXISTS e LEFT JOIN in termini di tempo di esecuzione, come mostrato sotto:

Fino a questo passo, possiamo dedurre dalle statistiche IO e TIME che i metodi che usano i comandi SQL NOT EXISTS e LEFT JOIN agiscono nel modo migliore, con le migliori prestazioni generali. Ma i piani di esecuzione delle query ci diranno lo stesso risultato? Controlliamo i piani di esecuzione generati dalle query precedenti utilizzando ApexSQL Plan, uno strumento per l’analisi dei piani di query di SQL Server.
La finestra di riepilogo dei piani di esecuzione, qui sotto, mostra che i metodi che usano i comandi SQL NOT EXISTS e LEFT JOIN hanno i costi di esecuzione minori, e il metodo che usa il comando NOT IN ha il costo di query più pesante, come mostrato qui sotto:

Immergiamoci profondamente per capire come si comporta ogni metodo studiando i piani di esecuzione di questi metodi.
Il piano di esecuzione per la query che usa il comando NOT IN è un piano complesso con una serie di operatori pesanti che eseguono operazioni di looping e di conteggio. Quello su cui ci concentreremo qui, ai fini del confronto delle prestazioni, sono gli operatori Nested Loops. Sotto gli operatori Nested Loops, potete vedere che questi operatori non sono veri e propri operatori di join, eseguono qualcosa chiamato Left Anti Semi Join. Questo operatore di join parziale restituirà tutte le righe della prima tabella di sinistra senza righe corrispondenti nella seconda tabella di destra, saltando tutte le righe corrispondenti tra le due tabelle. L’operatore più pesante nel seguente piano di esecuzione generato dalla query utilizzando il comando NOT IN è l’operatore Row Count Spool, che esegue scansioni sulla tabella non ordinata Category_B, contando quante righe vengono restituite, e restituisce solo il conteggio delle righe senza alcun dato, solo per scopi di controllo dell’esistenza delle righe. Il piano di esecuzione sarà il seguente:
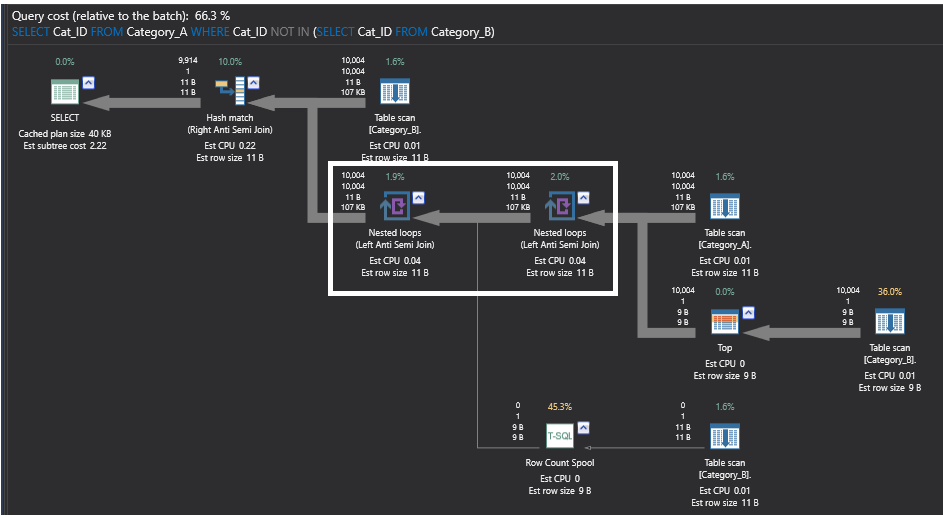
Il piano di esecuzione sottostante che è generato dalla query utilizzando il comando SQL NOT EXIST è più semplice del piano precedente, con l’operatore più pesante in quel piano è l’operatore Hash Match che ancora una volta esegue un’operazione di join parziale Left Anti Semi Join che controlla l’esistenza di righe non abbinate come descritto in precedenza. Questo piano sarà il seguente:
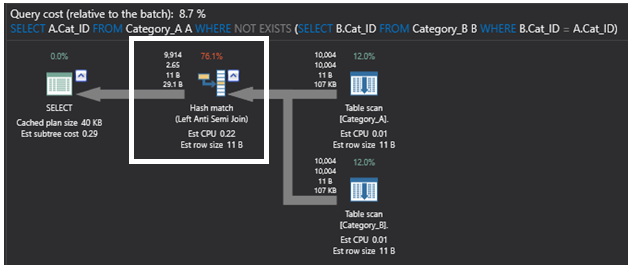
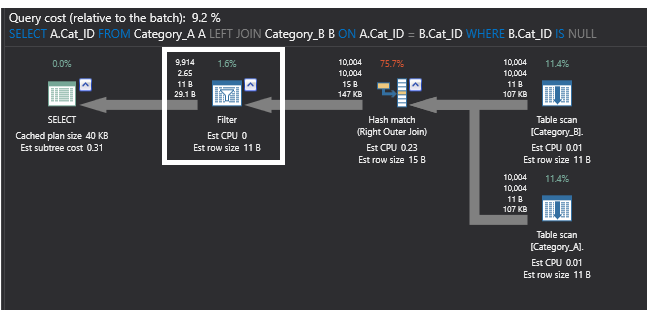
Confrontando il precedente piano di esecuzione generato dalla query che utilizza il comando SQL NOT EXISTS con il piano di esecuzione sottostante che è generato dalla query utilizzando il comando LEFT JOIN, il nuovo piano sostituisce il join parziale con un operatore FILTER che esegue il filtraggio IS NULL per i dati restituiti dall’operatore Right OUTER JOIN, che restituisce le righe corrispondenti dalla seconda tabella che possono includere duplicati. Questo piano sarà come mostrato di seguito:
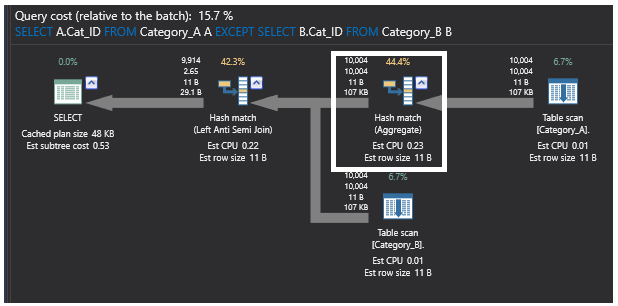
L’ultimo piano di esecuzione generato dalla query che utilizza il comando EXCEPT contiene anche l’operazione di join parziale Left Anti Semi Join che controlla l’esistenza di righe non abbinate come mostrato precedentemente. Esegue anche un’operazione di Aggregazione a causa delle grandi dimensioni della tabella e dei record non ordinati su di essa. Il processo Hash Aggregate crea una tabella hash nella memoria, che lo rende un’operazione pesante, e un valore hash sarà calcolato per ogni riga elaborata e per ogni valore hash calcolato. Dopo di che, controlla le righe nel secchio di hash risultante per le righe che si uniscono. Il piano sarà come mostrato di seguito:
Possiamo concludere nuovamente dai precedenti piani di esecuzione generati da ogni comando utilizzato che i due metodi migliori sono quelli che utilizzano i comandi SQL NOT EXISTS e LEFT JOIN. Ricordiamo che i dati nelle tabelle precedenti non sono ordinati a causa dell’assenza degli indici. Quindi, creiamo un indice sulla colonna di unione, Cat_ID, in entrambe le tabelle usando lo script T-SQL qui sotto:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
USE
GO
CREATE NONCLUSTERED INDEX ON .
(
ASC
)
GO
CREARE INDEX NONCLUSTERED SU .
(
ASC
)
GO
|
La finestra di riepilogo dei piani di esecuzione generata utilizzando ApexSQL Plan dopo aver eseguito le precedenti istruzioni SELECT, mostra che il metodo che usa il comando SQL NOT EXISTS è ancora il migliore e quello che usa il comando EXCEPT è migliorato chiaramente dopo aver aggiunto gli indici alle tabelle, come mostrato di seguito:

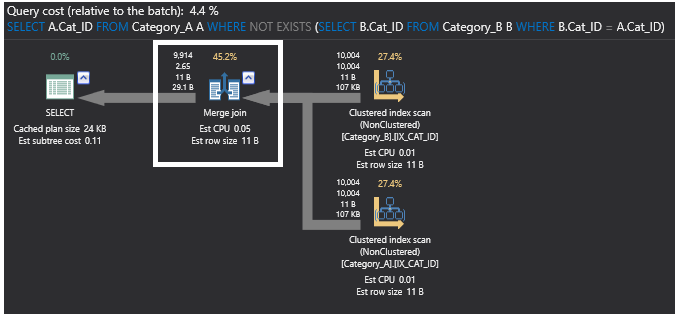
Controllando il piano di esecuzione per il comando SQL NOT EXISTS, la precedente operazione di join parziale viene eliminata ora e sostituita dall’operatore Merge Join, poiché i dati sono ordinati ora nelle tabelle dopo aver aggiunto gli indici. Il nuovo piano sarà come mostrato di seguito:
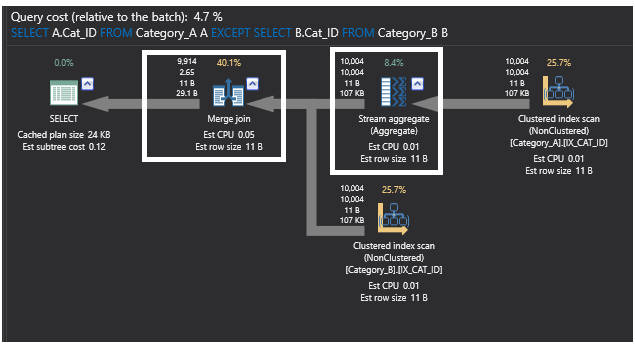
La query che utilizza il comando EXCEPT è migliorata chiaramente dopo aver aggiunto gli indici alle tabelle ed è diventata uno dei metodi migliori per raggiungere il nostro obiettivo. Questo appare anche nel piano di esecuzione della query qui sotto, in cui la precedente operazione di join parziale è anche sostituita dall’operatore Merge Join, poiché i dati sono ordinati aggiungendo gli indici. Anche l’operatore Hash Aggregate è ora sostituito da un operatore Stream Aggregate, poiché aggrega i dati ordinati dopo aver aggiunto gli indici.
Il nuovo piano sarà il seguente:
Conclusione:
SQL Server ci fornisce diversi modi per recuperare gli stessi dati, lasciando allo sviluppatore di SQL Server il compito di seguire il proprio approccio di sviluppo per ottenere ciò. Per esempio, ci sono diversi modi che possono essere utilizzati per recuperare dati da una tabella che non esistono in un’altra tabella. In questo articolo, abbiamo descritto come ottenere tali dati usando i comandi T-SQL NOT IN, SQL NOT EXISTS, LEFT JOIN e EXCEPT dopo aver fornito una breve descrizione di ogni comando e confrontato le prestazioni di queste query. Concludiamo, in primo luogo, che l’uso dei comandi SQL NOT EXISTS o LEFT JOIN sono la scelta migliore da tutti gli aspetti della performance. Abbiamo provato anche ad aggiungere un indice sulla colonna di unione su entrambe le tabelle, dove la query che usa il comando EXCEPT è migliorata chiaramente e ha mostrato prestazioni migliori, oltre al comando SQL NOT EXISTS che rimane la scelta migliore in assoluto.
Link utili
- EXISTS (Transact-SQL)
- Sottoquery con EXISTS
- Operatori Set – EXCEPT e INTERSECT (Transact-SQL)
- Operatore Showplan Left Anti Semi Join
- Autore
- Post recenti
 Ahmad Yaseen
Ahmad YaseenÈ un Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate e Microsoft Certified Trainer.
Inoltre, contribuisce con i suoi consigli SQL in molti blog.
Vedi tutti i post di Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers – February 11, 2021
- Come monitorare Azure Data Factory – 15 gennaio 2021
- Utilizzo del controllo delle fonti in Azure Data Factory – 12 gennaio 2021