Este artículo le ofrece una comparación del rendimiento de NOT IN, SQL Not Exists, SQL LEFT JOIN y SQL EXCEPT.
La biblioteca de comandos T-SQL, disponible en Microsoft SQL Server y que se actualiza en cada versión con nuevos comandos y mejoras de los ya existentes, nos proporciona diferentes formas de realizar una misma acción. Además de un juego de herramientas de comandos en constante evolución, diferentes desarrolladores aplicarán diferentes técnicas y enfoques a los mismos conjuntos de problemas y desafíos
Por ejemplo, tres desarrolladores diferentes de SQL Server pueden obtener los mismos datos utilizando tres consultas diferentes, teniendo cada desarrollador su propio enfoque para escribir las consultas T-SQL para recuperar o modificar los datos. Pero el administrador de la base de datos no estará necesariamente contento con todos estos enfoques, ya que busca estos métodos desde diferentes aspectos en los que no se concentran. Aunque todos ellos pueden obtener el mismo resultado requerido, cada consulta se comportará de manera diferente, consumirá una cantidad diferente de recursos de SQL Server con tiempos de ejecución diferentes. Todos estos parámetros en los que se concentra el administrador de la base de datos conforman el rendimiento de la consulta. Y es la regla del administrador de la base de datos aquí para afinar el rendimiento de estas consultas y elegir el mejor método con el mínimo efecto posible en el rendimiento general de SQL Server.
En este artículo, vamos a describir las diferentes formas que se pueden utilizar para recuperar datos de una tabla que no existe en otra tabla y comparar el rendimiento de estos diferentes enfoques. Estos métodos utilizarán los comandos T-SQL NOT IN, SQL NOT EXISTS, LEFT JOIN y EXCEPT. Antes de comenzar la comparación de rendimiento entre los diferentes métodos, proporcionaremos una breve descripción de cada uno de estos comandos T-SQL.
El comando SQL NOT IN permite especificar múltiples valores en la cláusula WHERE. Puede imaginarlo como una serie de comandos NOT EQUAL TO que están separados por la condición OR. El comando NO IN compara los valores de una columna específica de la primera tabla con los valores de otra columna de la segunda tabla o de una subconsulta y devuelve todos los valores de la primera tabla que no se encuentran en la segunda tabla, sin realizar ningún filtro para los valores distintos. El NULL es considerado y devuelto por el comando NOT IN como un valor.
El comando SQL NOT EXISTS se utiliza para comprobar la existencia de valores específicos en la subconsulta proporcionada. La subconsulta no devolverá ningún dato; devuelve valores TRUE o FALSE dependiendo de la comprobación de existencia de valores de la subconsulta.
El comando LEFT JOIN se utiliza para devolver todos los registros de la primera tabla izquierda, los registros coincidentes de la segunda tabla derecha y valores NULL de la parte derecha para los registros de la tabla izquierda que no tienen coincidencia en la tabla derecha.
El comando EXCEPT se utiliza para devolver todos los registros distintos de la primera sentencia SELECT que no se devuelven de la segunda sentencia SELECT, con cada sentencia SELECT se considerará como un conjunto de datos independiente. En otras palabras, devuelve todos los registros distintos del primer conjunto de datos y elimina de ese resultado los registros que se devuelven del segundo conjunto de datos. Puede imaginarlo como una combinación del comando SQL NOT EXISTS y la cláusula DISTINCT. Tenga en cuenta que los conjuntos de datos izquierdo y derecho del comando EXCEPT deben tener el mismo número de columnas.
Ahora, vamos a ver, en términos prácticos, cómo podríamos recuperar datos de una tabla que no existen en otra tabla utilizando diferentes métodos y comparar el rendimiento de estos métodos para concluir cuál se comporta de la mejor manera. Comenzaremos creando dos nuevas tablas, utilizando el script T-SQL que se muestra a continuación:
|
1
2
3
4
. 5
6
7
8
9
10
11
12
|
USE SQLShackDemo
GO
CREATE TABLE Category_A
( Cat_ID INT ,
Nombre_del_Gato VARCHAR(50)
)
GO
CREAR TABLA Categoría_B
( ID_del_Gato INT ,
Nombre_Gato VARCHAR(50)
)
GO
|
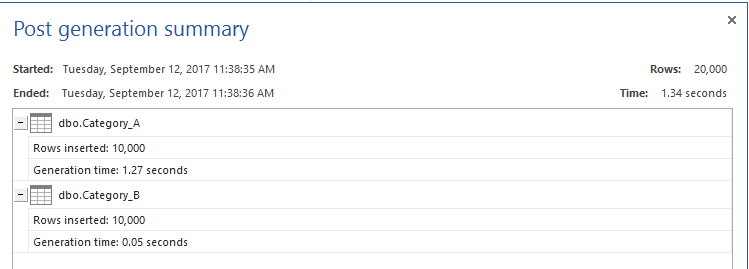
Las tablas de prueba ya están listas. Habilitaremos las estadísticas TIME e IO para utilizar estas estadísticas para comparar el rendimiento de los diferentes métodos. Después prepararemos las consultas T-SQL que se utilizan para extraer los datos que existen en la tabla Categoría_A pero que no existen en la tabla Categoría_B utilizando cuatro métodos; el comando NOT IN, el comando SQL NOT EXISTS, el comando LEFT JOIN y finalmente el comando EXCEPT. Esto se puede lograr utilizando el script T-SQL que se muestra a continuación:
|
1
2
3
4
5
6
7
8
9
10
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
28
29
30
USE SQLShackDemo
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
— NOT INT
SELECT Cat_ID
FROM Category_A WHERE Cat_ID NOT IN (SELECT Cat_ID FROM Category_B)
GO
— NOT EXISTS
SELECT A.Cat_ID
FROM Category_A A WHERE NOT EXISTS (SELECT B.Cat_ID FROM Category_B B WHERE B.Cat_ID = A.Cat_ID)
GO
— LEFT JOIN
SELECT A.Cat_ID
FROM Category_A A
LEFT JOIN Category_B B ON A.Cat_ID = B.Cat_ID
WHERE B.Cat_ID IS NULL
GO
— EXCEPT
SELECT A.Cat_ID
FROM Category_A A
EXCEPT
SELECT B.Cat_ID
FROM Category_B B
GO
|
Si ejecuta el script anterior, comprobará que los cuatro métodos devolverán el mismo resultado, como se muestra en el siguiente resultado que contiene el número de registro devuelto por cada comando:
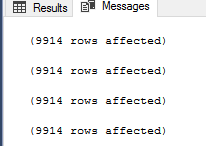
En este paso, el desarrollador de SQL Server estará contento, ya que cualquier método que utilice, le devolverá el mismo resultado. Pero, ¿qué pasa con el administrador de la base de datos de SQL Server que necesita comprobar el rendimiento de cada método? Si revisamos las estadísticas de IO y TIME que se generan tras ejecutar el script anterior, verá que el script que utiliza el comando NOT IN realiza 10062 lecturas lógicas sobre la tabla Category_B, tarda 228ms en completarse con éxito y 63ms de tiempo de CPU como se muestra a continuación:

Por otro lado, el script que utiliza el comando SQL NOT EXISTS realiza sólo 29 lecturas lógicas en la tabla Category_B, tarda 154ms en completarse con éxito y 15ms del tiempo de CPU, lo que es mucho mejor que el método anterior que utiliza NOT IN desde todos los aspectos, como se muestra a continuación:

Para el script que utiliza el comando LEFT JOIN, realiza el mismo número de lecturas lógicas que el método anterior de SQL NOT EXISTS, que son 29 lecturas lógicas, tarda 151ms en completarse con éxito y 16ms del tiempo de CPU, que es de alguna manera similar a las estadísticas derivadas del método anterior de SQL NOT EXISTS, como se muestra a continuación:

Por último, las estadísticas generadas tras ejecutar el método que utiliza el comando EXCEPT muestran que vuelve a realizar 29 lecturas lógicas, tarda 218ms en completarse con éxito y consume 15ms del tiempo de CPU, lo que es peor que los métodos SQL NOT EXISTS y LEFT JOIN en cuanto a tiempo de ejecución, como se muestra a continuación:

Hasta este paso, podemos derivar de las estadísticas de IO y TIME que los métodos que utilizan los comandos SQL NOT EXISTS y LEFT JOIN actúan de la mejor manera, con el mejor rendimiento global. ¿Pero los planes de ejecución de las consultas nos dirán el mismo resultado? Comprobemos los planes de ejecución que se generan a partir de las consultas anteriores utilizando ApexSQL Plan, una herramienta de análisis de planes de consulta de SQL Server.
La ventana de resumen de costes de los planes de ejecución, a continuación, muestra que los métodos que utilizan los comandos SQL NOT EXISTS y LEFT JOIN son los que menos costes de ejecución tienen, y el método que utiliza el comando NOT IN es el que más coste de consulta tiene, como se muestra a continuación:

Seamos profundos para entender cómo se comporta cada método estudiando los planes de ejecución de estos métodos.
El plan de ejecución de la consulta que utiliza el comando NOT IN es un plan complejo con varios operadores pesados que realizan operaciones de bucle y de conteo. En lo que nos concentraremos aquí, a efectos de comparación del rendimiento, son los operadores de bucles anidados. Bajo los operadores de Bucles Anidados, puede ver que estos operadores no son verdaderos operadores de unión, realiza algo llamado Left Anti Semi Join. Este operador de unión parcial devolverá todas las filas de la primera tabla de la izquierda que no coincidan con las de la segunda tabla de la derecha, omitiendo todas las filas que coincidan entre las dos tablas. El operador más pesado en el siguiente plan de ejecución generado por la consulta utilizando el comando NOT IN es el operador Row Count Spool, que realiza escaneos en la tabla Category_B sin clasificar, contando cuántas filas se devuelven, y devuelve sólo el recuento de filas sin ningún dato, sólo para fines de comprobación de existencia de filas. El plan de ejecución será el siguiente:
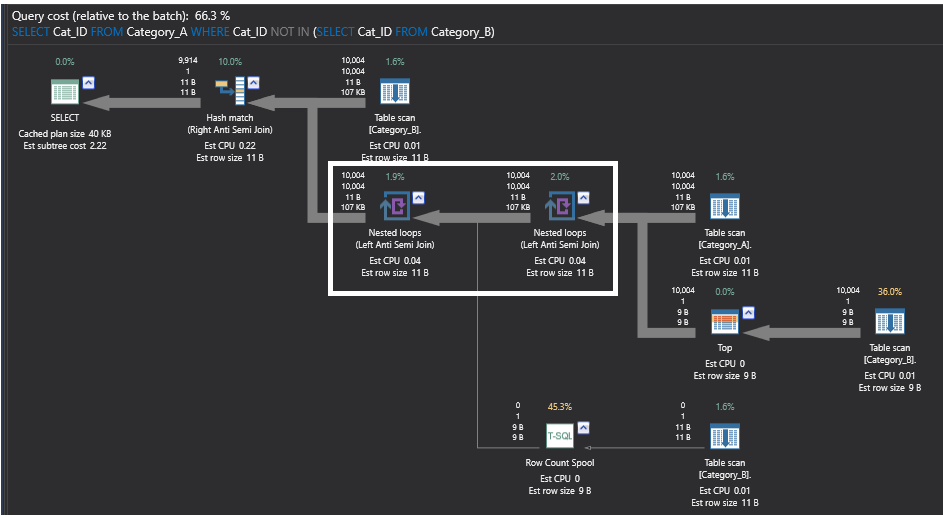
El siguiente plan de ejecución que genera la consulta utilizando el comando SQL NOT EXIST es más sencillo que el plan anterior, siendo el operador más pesado de ese plan el operador Hash Match que vuelve a realizar una operación de unión parcial Left Anti Semi Join que comprueba la existencia de filas no coincidentes como se ha descrito anteriormente. Este plan será el siguiente:
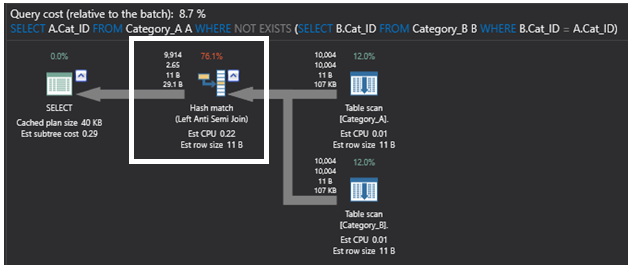
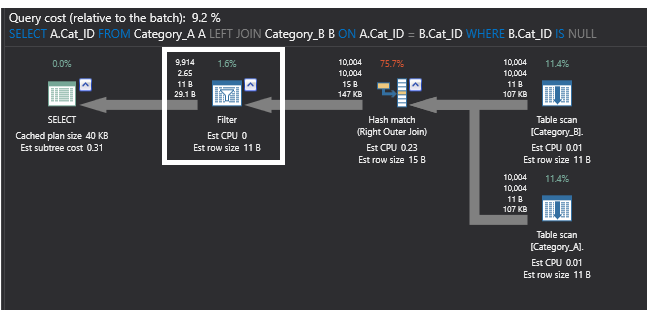
Comparando el anterior plan de ejecución generado por la consulta que utiliza el comando SQL NOT EXISTS con el siguiente plan de ejecución que es generado por la consulta que utiliza el comando LEFT JOIN, el nuevo plan sustituye el join parcial por un operador FILTER que realiza el filtrado IS NULL para los datos devueltos por el operador Right OUTER JOIN, que devuelve las filas coincidentes de la segunda tabla que pueden incluir duplicados. Este plan será como se muestra a continuación:
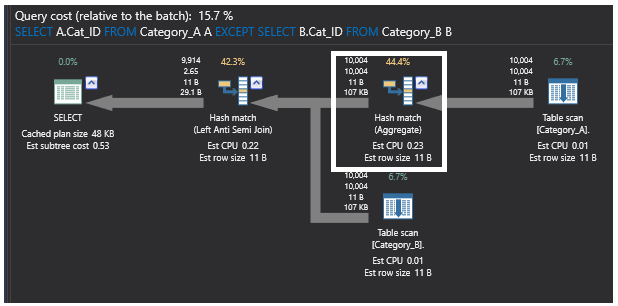
El último plan de ejecución generado por la consulta que utiliza el comando EXCEPT contiene también la operación de unión parcial Left Anti Semi Join que comprueba la existencia de filas no coincidentes como se ha mostrado anteriormente. También realiza una operación de Agregación debido al gran tamaño de la tabla y a los registros no ordenados en ella. El proceso de Hash Aggregate crea una tabla hash en la memoria, lo que hace que sea una operación pesada, y se calculará un valor hash para cada fila procesada y para cada valor hash calculado. Después de eso, comprueba las filas en el cubo de hash resultante para las filas de unión. El plan será como se muestra a continuación:
Podemos concluir de nuevo a partir de los planes de ejecución anteriores generados por cada comando utilizado que los dos mejores métodos son los que utilizan los comandos SQL NOT EXISTS y LEFT JOIN. Recordemos que los datos de las tablas anteriores no están ordenados debido a la ausencia de los índices. Por lo tanto, vamos a crear un índice en la columna de unión, el Cat_ID, en ambas tablas utilizando el script T-SQL siguiente:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
USE
GO
CREAR ÍNDICE NO CLASIFICADO EN .
(
ASC
) GO
CREAR INDEX NONCLUSTERED EN .
(
ASC
GO
|
La ventana de resumen de costes de los planes de ejecución generada con ApexSQL Plan tras ejecutar las sentencias SELECT anteriores, muestra que el método que utiliza el comando SQL NOT EXISTS sigue siendo el mejor y el que utiliza el comando EXCEPT mejoró claramente después de añadir los índices a las tablas, como se muestra a continuación:

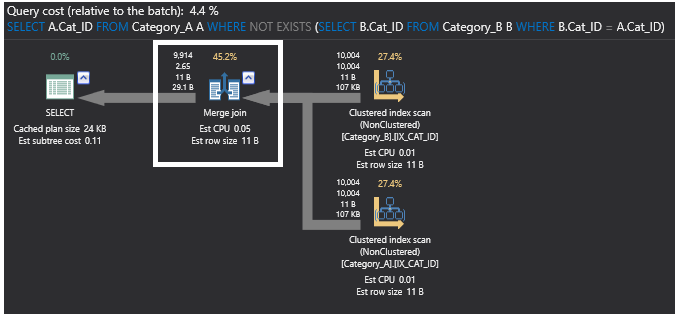
Comprobando el plan de ejecución del comando SQL NOT EXISTS, la anterior operación de unión parcial se elimina ahora y se sustituye por el operador Merge Join, ya que los datos están ordenados ahora en las tablas tras añadir los índices. El nuevo plan será como se muestra a continuación:
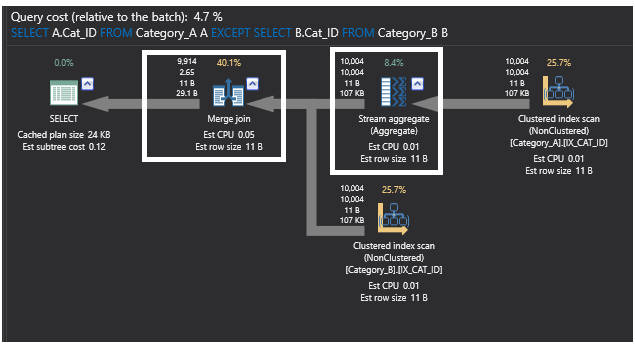
La consulta que utiliza el comando EXCEPT mejoró claramente después de añadir los índices a las tablas y se convirtió en uno de los mejores métodos para lograr nuestro objetivo aquí. Esto también apareció en el siguiente plan de ejecución de la consulta, en el que la anterior operación de unión parcial también se sustituye por el operador Merge Join, ya que los datos se ordenan añadiendo los índices. El operador Hash Aggregate también se sustituye ahora por un operador Stream Aggregate, ya que agrega un dato ordenado después de añadir los índices.
El nuevo plan será el siguiente:
Conclusión:
SQL Server nos proporciona diferentes formas de recuperar un mismo dato, dejando al desarrollador de SQL Server que siga su propio enfoque de desarrollo para conseguirlo. Por ejemplo, hay diferentes formas que se pueden utilizar para recuperar datos de una tabla que no existen en otra tabla. En este artículo, describimos cómo obtener dichos datos utilizando los comandos T-SQL NOT IN, SQL NOT EXISTS, LEFT JOIN y EXCEPT después de proporcionar una breve descripción de cada comando y comparar el rendimiento de estas consultas. Concluimos, en primer lugar, que el uso de los comandos SQL NOT EXISTS o LEFT JOIN son la mejor opción desde todos los aspectos de rendimiento. También probamos a añadir un índice en la columna de unión en ambas tablas, donde la consulta que utiliza el comando EXCEPT mejoró claramente y mostró un mejor rendimiento, además del comando SQL NOT EXISTS que sigue siendo la mejor opción en general.
Enlaces útiles
- EXISTS (Transact-SQL)
- Subconsultas con EXISTS
- Operadores de unión – EXCEPT e INTERSECT (Transact-SQL)
- Operador Showplan Left Anti Semi Join
- Autor
- Postes Recientes

Es un Microsoft Certified Solution Expert en Gestión de Datos y Analítica, Microsoft Certified Solution Associate en Administración y Desarrollo de Bases de Datos SQL, Azure Developer Associate y Microsoft Certified Trainer.
Además, está contribuyendo con sus consejos SQL en muchos blogs.
Ver todos los posts de Ahmad Yaseen
- Preguntas y respuestas de la entrevista de Azure Data Factory – 11 de febrero, 2021
- Cómo supervisar Azure Data Factory – 15 de enero de 2021
- Utilizando Source Control en Azure Data Factory – 12 de enero de 2021